From predicting a sales forecast to predicting the shortest route to reach a destination, Data Science has a wide range of applications across various industries. Engineering, marketing, sales, operations, supply chain, and whatnot. You name it, and there is an application of data science. And the application of data science is growing exponentially! The situation is such that the demand for people with knowledge in data science is higher than academia is currently supplying!
Starting with this article, I will be writing a series of blog posts on how to solve a Data Science problem in real-life and in data science competitions.
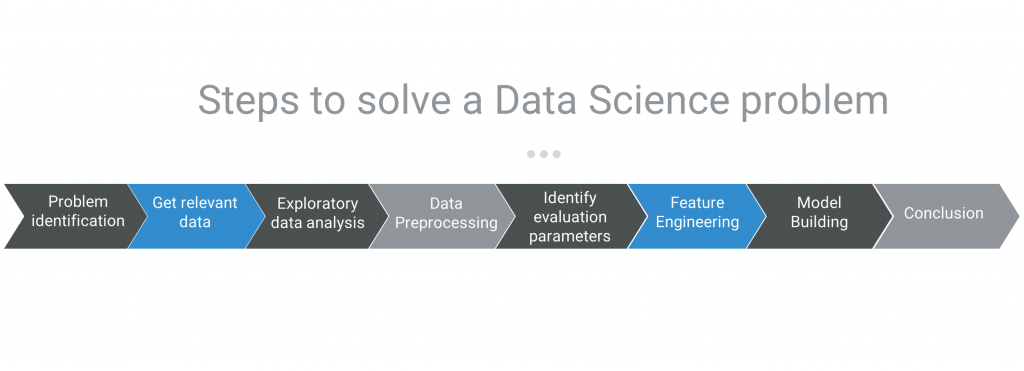
While there could be different approaches to solving a problem, the broad structure to solving a Data Science problem remains more or less the same. The approach that I usually follow is mentioned below.
Step 1: Identify the problem and know it well:
In real-life scenarios: Identification of a problem and understanding the problem statement is one of the most critical steps in the entire process of solving a problem. One needs to do high-level analysis on the data and talk to relevant functions (could be marketing, operations, technology team, product team, etc) in the organization to understand the problems and see how these problems can be validated and solved through data.

To give a real-life example, I will briefly take you through a problem that I worked on recently. I was performing the customer retention analysis of an e-learning platform. This particular case is a classification problem where the target variable is binary i.e one needs to predict whether a user would be an active learner on the platform or not in the next ‘x’ days, based on her behavior/interaction on the platform for the last ‘y’ days.
As I just mentioned, identification of the problem is one of the most critical steps. In this particular case, it was identifying that there is an issue with the user retention on the platform. And as an immediate actionable step, it is important to understand the underlying factors that are causing users to leave the platform (or become non-active learners). Now the question is how do we do this.
In the case of Data Science challenges, the problem statement is generally well defined, and all you need to do is clearly understand it and come up with a suitable solution. If needed, an additional primary and secondary research about the problem statement should be done as it helps in coming up with a better solution. If needed additional variables and cross features can be created based on the subject expertise.
Step 2: Get the relevant data:
In real-life scenarios: Once the problem is identified, Data scientists need to talk to relevant functions (could be marketing, operations, technology team, product team, etc) in the organization to understand the possible trigger points of the problem and identify relevant data to perform the analysis. Once this is done, all the relevant data should be extracted from the database.
Continuing my narration of the problem statement I recently worked on, I did a thorough audit of the platform and the user journey and what actions users performed when on the platform. I did the audit with the help of the product and development team. This audit gave me a thorough understanding of the database architecture and potential data logs that were captured and could be considered for the analysis. An extensive list of data points (variables or features) were collated with the help of relevant stakeholders in the organization.
In essence, usually, this step not only helps in understanding the DB architecture and data extraction process, but it would also help in identifying potential issues within the DB (if any), missing logs in the user journey that were not captured previously, etc. This would further help the development team to add the missing logs and enhance the architecture of the DB.
Now that we have done the data extraction, we can proceed with the data pre-processing step in order to prepare the data for the analysis.
Data Science Challenge: In the case of Data Science Challenges, a dataset is often provided.
Step 3: Perform exploratory data analysis:
To begin with, data exploration is done to understand the patterns of each of the variables. Some basic plots such as histograms and box plots are analyzed to check if there are any outliers, class imbalances, missingness, and anomalies in the dataset. Data exploration and data pre-processing have a very close correlation and often they are clubbed together.
Step 4: Pre-process the data:
In order to get reliable, reproducible and unbiased data analysis certain pre-processing steps are to be followed. In my recent study, I followed the below-mentioned steps – these are some of the standard steps that are followed while performing any analysis:
- Data Cleaning and treating missingness in the data: Often data comes with missing values and it is always a struggle to get quality data.
- Standardization/normalization (if needed): Often variables in a dataset come with a wide range of data, performing standardization/normalization would bring them to a common scale so that it could further help in implementing various machine learning models (where standardization/normalization is a pre-requisite to apply such models).
- Outlier detection: It is important to know if there are any anomalies in the dataset and treat them if required. Else you might end up getting skewed results.
- Splitting the data into test data and training data for model training and evaluation purpose: The data should be split into two parts
- Train dataset: Models are trained on the training dataset
- Test dataset: Once the model is built on the training dataset, it should be tested on the test data to check for its performance.
The pre-processing step is common for both real-life data science problems and competitions alike. Now that we have pre-processed the data, we can move to defining the model evaluation parameters and exploring the data further.
Step 5: Define model evaluation parameters:
Arriving at the right parameters to assess a model is critical before performing the analysis.
Based on various parameters and expressions of interest of the problem, one needs to define model evaluation parameters. Some of the widely used model evaluation performance are listed below:
- Receiver Operating Characteristic (ROC): This is a visualization tool that plots the relationship between true positive rate and false positive rate of a binary classifier. ROC curves can be used to compare the performance of different models by measuring the area under the curve (AUC) of its plotted scores, which ranges from 0.0 to 1.0. The greater this area, the better the algorithm is to find a specific feature.
- Classification Accuracy/Accuracy
- Confusion matrix
- Mean Absolute Error
- Mean Squared Error
- Precision, Recall
The model performance evaluation should be done on the test dataset created during the preprocessing step, this test dataset should remain untouched during the entire model training process.
Coming to the customer retention analysis that I worked on, my goal was to predict the users who would leave the platform or become non-active learners. In this specific case, I picked a model that has a good true positive rate in its confusion matrix. Here, true positive means, the cases in which the model has predicted a positive result (i.e user left the platform or user became a non-active learner) that is the same as the actual output. Let’s not worry about the process of picking the right model evaluation parameter, I will give a detailed explanation in the next series of articles.
Data Science challenges: Often, the model evaluation parameters are given in the challenge.
Step 7: Perform feature engineering:
This step is performed in order to know:
- Important features that are to be used in the model (basically we need to remove the redundant features if any). Metrics such as AIC, BIC are used to identify the redundant features, there are built-in packages such as StepAIC (forward and backward feature selection) in R that help in performing these steps. Also, algorithms such as Boruta are usually helpful in understanding the feature importance.
In my case, I used Boruta to identify the important features that are required for applying a machine learning model. In general, featuring has following steps:
- Transform features: Often a feature or a variable in the dataset might not have a linear relationship with the target variable. We would get to know this in the exploratory data analysis. I usually try and apply various transformations such as inverse, log, polynomial, logit, probit etc that closely matches the relationship between the target variable and the feature
- Create cross features or new relevant variables- We can create cross features based on domain knowledge. For example, if we were given batsmen profile (say Sachin or Virat) with the following data points: name, no. of matches played, total runs scored — we can create a new cross-feature called batting average = runs scored/matches played.
Once we run the algorithms such as Boruta, we would get feature importance. Now that we know what all features are important, we can proceed to model building exercise.
Step 8: Build the model:
Various machine learning models can be tried based on the problem statement. We can start fitting various models, some of the examples include linear regression, logistic regression, random forest, neural networks etc and enhance the fitted models further (through cross-validation, tuning the hyper-parameters etc).
Step 9: Perform model comparison:
Now that we have built various models, it is extremely important for us to compare them and identify the best one based on defined problem and model evaluation parameters (defined in step 5).
In my example, I experimented with logistic regression, random forest, decision tree, neural networks, and extreme gradient boosting. Out of all, extreme gradient boosting turned out to be the best model for the given data and problem at hand.
Step 10: Communicate the result:
Data visualization and proper interpretation of the models should be done in this step. This would provide valuable data insights that would immensely help various teams in an organization to make informed data-driven decisions. The final data visualization and communication should be very intuitive such that anyone can understand and interpret the results. Further, the end-user who consumes the data should be able to turn them into actionable points that could further enhance the growth of the organization. Well, this summarizes the steps for solving a data science problem.
Happy learning!
Become a guide. Become a mentor.
I welcome you to share your experience in data science – learning journey, competition, data science projects, and anything that is related to Data Science. Your learnings could help a large number of aspiring data scientists! Interested? Submit here.
Good article Chanukya…. congratulations I wish you good luck