Learning Objectives
- Supervised and Unsupervised Learning
- Importance of Unsupervised Learning
- Why Unsupervised Learning?
- Applications of Unsupervised Learning
- Unsupervised Learning Use Cases
Supervised Learning
If you have some previous Machine Learning knowledge, you might be working with datasets that have both input variables and target variables (labels for the data). Whether you need to predict the survival rate of a person in Titanic Dataset where Survival Rate was already given or predict the House Price according to house characteristics where the house prices were provided.
The algorithms that work on such datasets are known as Supervised Learning Algorithms.
It is called supervised learning because the process of an algorithm learning from the training dataset can be thought of as a teacher supervising the learning process. We know the correct answers, the algorithm iteratively makes predictions on the training data and is corrected by the teacher. Learning stops when the algorithm achieves an acceptable level of performance.
Unsupervised Learning
Unsupervised learning is where you have unlabeled data (or no target variable) in the dataset.
The goal of Unsupervised Learning Algorithms is to find some structure in the dataset.
These are called unsupervised learning algorithms because unlike supervised learning, there are no correct answers and there is no teacher. Algorithms are left to their own to discover and present the interesting structure in the data.
Unsupervised Learning = Learning without labels

On the left (a classification problem), we can see the distinction between the data points clearly. They are either blue circles or red crosses. These are the labels of the data. Supervised Learning will be used in this case.
On the right, all the data points look alike. Unsupervised Learning will be used in this case. Finding some structure in this data might look like creating 2 groups shown by the red circles.
Importance of Unsupervised Learning
In the real world, most of the data is available in an unstructured format. Hence, it becomes extremely difficult to draw insights from them. Unsupervised Learning helps to draw similarities between the data and separate them into groups having unique labels. In this way, the unstructured data can be converted into a structured format.
Due to this cognitive power to draw insights, deduce patterns from the data, and learn from those, unsupervised learning is often compared to human intelligence.
Why Unsupervised Learning?
- Annotating (Labelling) large datasets is very costly and hence we can label only a few examples manually. Example: Speech Recognition.
- There may be cases where we don’t know how many/what classes is the data divided into. Example: Data Mining.
- We may want to use clustering (grouping) to gain some insight into the structure of the data before designing a classifier.
Applications of Unsupervised Learning
- Market Segmentation
Market segmentation is the practice of dividing consumers into groups based on shared needs, desires, and preferences. Using these categories, a business can adjust its product lines and marketing techniques to appeal to each group more effectively by addressing their specific needs.
E.g., A vehicle manufacturer that sells a luxury, higher end car brand would likely target an audience that has a higher income.
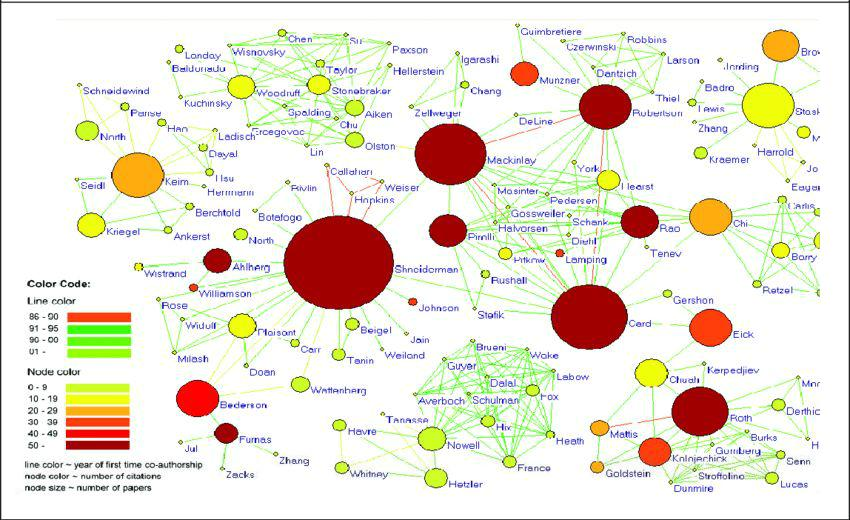
- Social Network Analysis(SNA)
SNA is the mapping and measuring of relationships between people, groups, organizations, computers, URLs, and other connected entities.
Eg. Social Network Sites like Facebook use SNA to identify and recommend potential friends based on friends-of-friends.
- Astronomical Data Analysis
“A simple visualization of a complicated data makes the science behind it seem obvious.” Unsupervised learning techniques help in clustering the galaxies based on certain characteristics.

Unsupervised Learning Use Cases
Unsupervised learning is broadly used for 2 things in Machine Learning:
- Clustering - deals with finding a structure in a collection of unlabeled data.
- Dimensionality Reduction - techniques that reduce the number of input variables in a dataset.
