Módulo 1: Introducción
Objetivos de aprendizaje
- Aprendizaje Supervisado y No Supervisado
- La importancia del Aprendizaje No Supervisado
- ¿Por qué el Aprendizaje No Supervisado?
- Aplicaciones del Aprendizaje No Supervisado
- Casos de Uso del Aprendizaje No Supervisado
Aprendizaje Supervisado
Si tienes algún conocimiento previo de Aprendizaje Automático, puede que estés trabajando con conjuntos de datos que tienen tanto variables de entrada como variables de destino (etiquetas para los datos). Ya sea que necesite predecir la tasa de supervivencia de una persona en el conjunto de datos del Titanic, donde la tasa de supervivencia ya fue dada, o predecir el precio de la casa de acuerdo con las características de la misma, donde los precios de la casa fueron proporcionados.
Los algoritmos que trabajan con estos conjuntos de datos se conocen como Algoritmos de Aprendizaje Supervisado.
Se llama aprendizaje supervisado porque el proceso de aprendizaje de un algoritmo a partir del conjunto de datos de entrenamiento puede considerarse como un profesor que supervisa el proceso de aprendizaje. Conocemos las respuestas correctas, el algoritmo realiza iterativamente predicciones sobre los datos de entrenamiento y es corregido por el profesor. El aprendizaje se detiene cuando el algoritmo alcanza un nivel de rendimiento aceptable.
Aprendizaje No Supervisado
El aprendizaje no supervisado es aquel en el que hay datos no etiquetados (o ninguna variable objetivo) en el conjunto de datos.
El objetivo de los algoritmos de aprendizaje no supervisado es encontrar alguna estructura en el conjunto de datos.
Se llaman algoritmos de aprendizaje no supervisado porque, a diferencia del aprendizaje supervisado, no hay respuestas correctas y no hay un profesor. Los algoritmos se dejan solos para descubrir y presentar la estructura interesante en los datos.
Aprendizaje No Supervisado = Aprendizaje sin etiquetas

Las traducciones exactas de la imagen anterior se pueden encontrar a continuación:
Aprendizaje Supervisado Aprendizaje No Supervisado
A la izquierda (un problema de clasificación), podemos ver claramente la distinción entre los puntos de datos. Son círculos azules o cruces rojas. Estas son las etiquetas de los datos. En este caso se utilizará el aprendizaje supervisado.
A la derecha, todos los puntos de datos se parecen. En este caso se utilizará el aprendizaje no supervisado. Encontrar alguna estructura en estos datos podría ser como crear 2 grupos mostrados por los círculos rojos.
Importancia del Aprendizaje No Supervisado
En el mundo real, la mayoría de los datos están disponibles en un formato no estructurado. Por lo tanto, resulta muy difícil extraer información de ellos. El aprendizaje no supervisado ayuda a establecer similitudes entre los datos y a separarlos en grupos con etiquetas únicas. De este modo, los datos no estructurados pueden convertirse en un formato estructurado.
Debido a este poder cognitivo para extraer ideas, deducir patrones de los datos y aprender de ellos, el aprendizaje no supervisado se compara a menudo con la inteligencia humana.
¿Por qué el Aprendizaje No Supervisado?
- Anotar (etiquetar) grandes conjuntos de datos es muy costoso, por lo que sólo podemos etiquetar manualmente unos pocos ejemplos. Ejemplo: Reconocimiento del habla.
- Puede haber casos en los que no sepamos en cuántas/qué clases están divididos los datos. Ejemplo: Minería de datos.
- Puede que queramos utilizar el clustering (agrupación) para conocer la estructura de los datos antes de diseñar un clasificador.
Aplicaciones del Aprendizaje No Supervisado
Segmentación del mercado
La segmentación del mercado es la práctica de dividir a los consumidores en grupos basados en necesidades, deseos y preferencias comunes. A partir de estas categorías, una empresa puede ajustar sus líneas de productos y sus técnicas de marketing para atraer a cada grupo de forma más eficaz, atendiendo a sus necesidades específicas.
Por ejemplo, un fabricante de vehículos que venda una marca de coches de lujo de gama alta probablemente se dirigirá a un público con mayores ingresos.
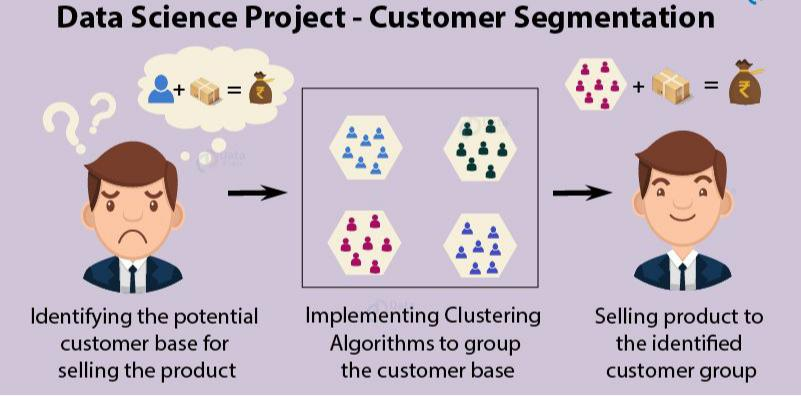
Las traducciones exactas de la imagen anterior se pueden encontrar a continuación:
Título: Proyecto de Ciencia de Datos - Segmentación de clientes Identificar el potencial de clientes base para vender el producto Implementar Algoritmos de Clustering para agrupar clientes base Venta de productos a los grupos identificados de clientes
Análisis de redes sociales (SNA)
El SNA es el mapeo y la medición de las relaciones entre personas, grupos, organizaciones, ordenadores, URLs y otras entidades conectadas.
Por ejemplo, los sitios de redes sociales como Facebook utilizan el SNA para identificar y recomendar amigos potenciales basándose en los amigos de los amigos.
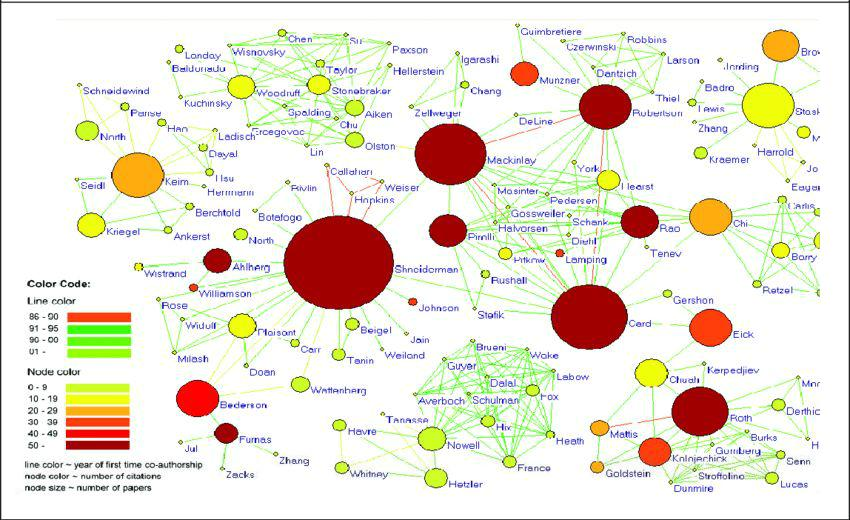
Las traducciones exactas de la imagen anterior se pueden encontrar a continuación:
Color de línea: Año del primer co-autor Color de nodo: Número de citaciones Tamaño de nodo: Number de artículos
- Análisis de datos astronómicos
"Una simple visualización de un dato complicado hace que la ciencia que hay detrás parezca obvia". Las técnicas de aprendizaje no supervisado ayudan a agrupar las galaxias en función de ciertas características.

Casos de uso del Aprendizaje No Supervisado
El aprendizaje no supervisado se utiliza ampliamente para 2 cosas en el aprendizaje automático:
- Clustering - trata de encontrar una estructura en una colección de datos sin etiquetar.
- Reducción de dimensionalidad - técnicas que reducen el número de variables de entrada en un conjunto de datos.

Las traducciones exactas de la imagen anterior se pueden encontrar a continuación: