Imagine an 18-year-old teenager who wants to build a personalized music recommendation app. The teenager starts with a pre-trained language model as the foundation. The model already has extensive knowledge about music, artists, and genres from its pre-training on internet text. However, it doesn't know the teenager's specific music taste or the nuances of their friend's preferences.
Source: Article at Labeller by Akshit Mehra
To fine-tune the model, the teenager gathers a dataset of their own music listening history and those of their friends. Each data point includes details like song preferences, liked genres, and favorite artists. Using this dataset, the teenager fine-tunes the model, training it to make personalized music recommendations based on individual preferences. The fine-tuned model becomes a powerful tool for creating a unique music discovery experience, leveraging its general music knowledge while adapting it to the teenager's specific taste and their friends' preferences. This illustrates how fine-tuning can help personalize and enhance the capabilities of a pre-trained language model for a specialized application.
Steps involved to Fine Tune a Large Language model
In order to Fine tune a large language models we need a dataset to train a pre-trained model. Let's consider an example of Fine-Tuning a large language model for a Question and Answering (QA) task on medical data, the steps involved are:
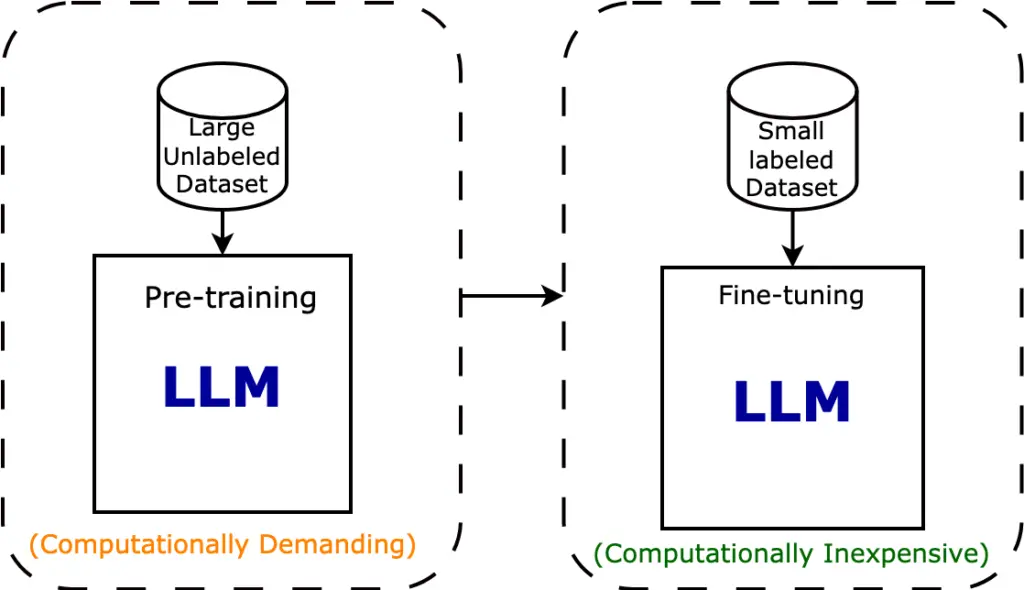
- Pre-training: The language model is pre-trained on a massive corpus of text from the internet. During this pre-training phase, it learns grammar, semantics, and some level of world knowledge. However, it knows nothing about medical data or specific medical questions and answers.
- Fine-tuning Data: You gather a dataset of medical questions, associated answers, and potentially additional relevant context. This dataset is specific to your task and consists of thousands of question-answer pairs or passages along with their corresponding answers.
- Tokenization/Text Encoding: You preprocess the medical questions, answers, and context. This includes tokenizing the text and converting it into a suitable format for the QA task. Typically, you'll encode the question and context together and generate answers from the model's predictions.
- Fine-tuning Objective: Define a task-specific objective. In this case, it's QA, where the model must answer questions based on the given context and generate accurate responses.
- Fine-tuning training: Take the pre-trained language model and further train it on your medical QA dataset. During fine-tuning, the model's internal parameters are adjusted to optimize its ability to answer questions accurately using the provided context. The model learns to understand medical terminology and context.
- Hyperparameter Tuning: Experiment with various hyperparameters like learning rate, batch size, and the number of training epochs. Fine-tuning these hyperparameters can significantly affect the model's performance. For example, a smaller learning rate might lead to more precise updates to the model's parameters, while a larger batch size can speed up training but might require more memory.
In addition to these steps, there are some additional considerations for fine-tuning a QA model on medical data:
- Domain-specific terminology: Medical data often contains complex and domain-specific terminology. It's essential to ensure that the model is exposed to a broad range of medical vocabulary during pre-training and fine-tuning.
- Ethical and privacy concerns: Medical data can be sensitive and subject to privacy regulations. Ensuring that data is de-identified and handling it with care is crucial.
Issues with Fine-tuning
- Even after the Fine-tuning, the learning parameters is massive or close to the parameters of actual pre-trained model.
- Many sought to mitigate this by adapting only some parameters or learning external modules for new tasks. This way, we only need to store and load a small number of task-specific parameters in addition to the pre-trained model for each task, greatly boosting the operational efficiency when deployed. However, existing techniques often introduce inference latency by extending model depth or reduce the model’s usable sequence length.
Parameter Efficient Fine Tuning (PeFT)
Efficient parameter fine-tuning methods, known as PEFT, provide a cost-effective means of adapting pre-trained language models (PLMs) to various practical applications. These methods enable substantial reductions in computational and storage requirements by fine-tuning only a limited number of additional model parameters. Recent state-of-the-art PEFT techniques have demonstrated the capability to achieve performance levels comparable to full fine-tuning, making them a cost-efficient choice.
LoRA- Low Rank Adaption
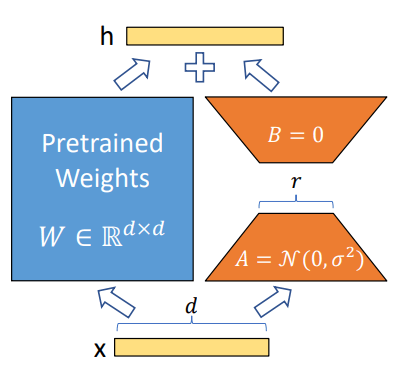
- Using LoRA, one can freeze the pre-trained model weights and inject trainable rank decomposition matrices into each layer of transformer architecture.
- No inference latency.
- Applying LoRA to any subset of weight matrices in a Neural network reduces the number of trainable parameters.
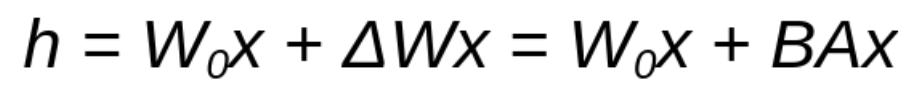
- Now let's consider the number of input parameters: 28*28 = 784. Let's apply LoRA eqn. Assume Rank = 4 as shown in LoRA Paper pg.5
- W0 = 784 x 784 = 614,656 parameters,
- The LoRA layers matrices A and B (BAx) together have 784 x 4 + 4 x 784 = 6,272 parameters.
- LoRA dense layer goes from 614,656 trainable parameters to 6,272 trainable parameters!