Note:
This is only for Advanced users how wants to dive deep into the Maths
Consider two sample sequence:
Example Sentence:
- Input: Hindi Sentence: "मैं खाना खा रहा हूँ"
- Output: English Translation: "I am eating"
Step 1: Tokenization:
Tokenization breaks down the sentences into individual words or tokens.
- Hindi Tokens: ["मैं", "खाना", "खा", "रहा", "हूँ"]
- English Tokens: ["I", "am", "eating"]
Step 2: Embedding:
Embedding is the process of representing words as numerical vectors in a continuous space. These vectors capture the semantic meaning of the words and allow the neural network to work with words as numerical values. Each word is mapped to a high-dimensional vector, where the dimensions represent different aspects of the word's meaning.
In the context of our Hindi-English translation example, let's look at the embeddings for the Hindi tokens:
1 2 3 4 5"मैं": [0.1, -0.2, 0.5] "खाना": [0.3, 0.7, -0.4] "खा": [0.2, 0.6, -0.1] "रहा": [-0.1, 0.9, 0.2] "हूँ": [0.4, -0.3, 0.8]
These embeddings are learned during the training process of the neural network and are updated to capture the relationships between words in the context of the specific task, such as translation. The network then uses these embeddings as inputs to understand and generate meaningful translations.
Step 3: Encoder:
Let's use a simplified encoder with only one time step for demonstration.
The Encoder Hidden State
For illustration, let's assume that our source sentence is "मैं खाना खा रहा हूँ" (I am eating) and we're processing the second word "खाना" (eating).
Here's what this hidden state represents:
- The first dimension (0.2) might capture the presence of the subject pronoun ("I").
- The second dimension (0.5) could represent the action of eating ("eating").
- The third dimension (-0.3) could capture some context about the verb tense ("am")
A reminder before we dive into Attention Score calculation:
There are different operations involved to calculate the Attention. Some Videos use different techniques as shown in the below diagram:
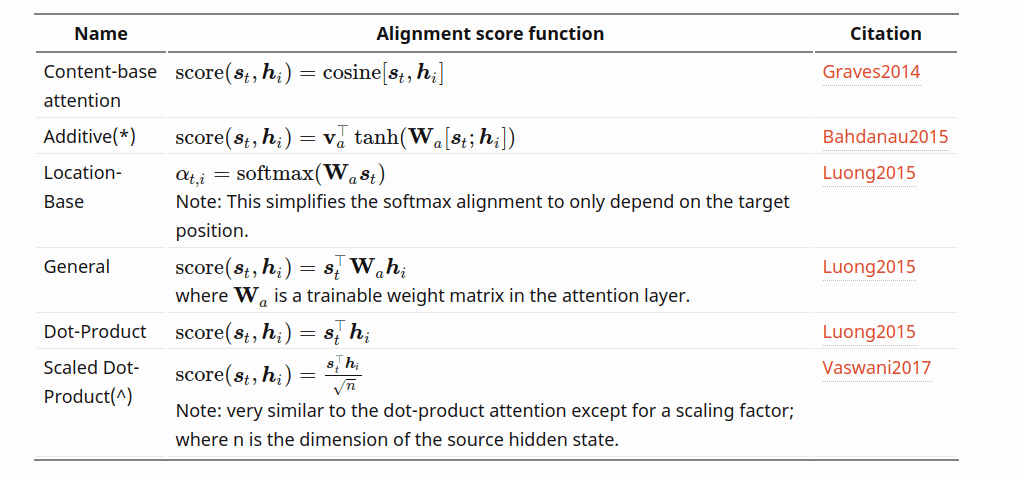
In our approach we will use Dot-Product
Step 4: Attention Scoring:
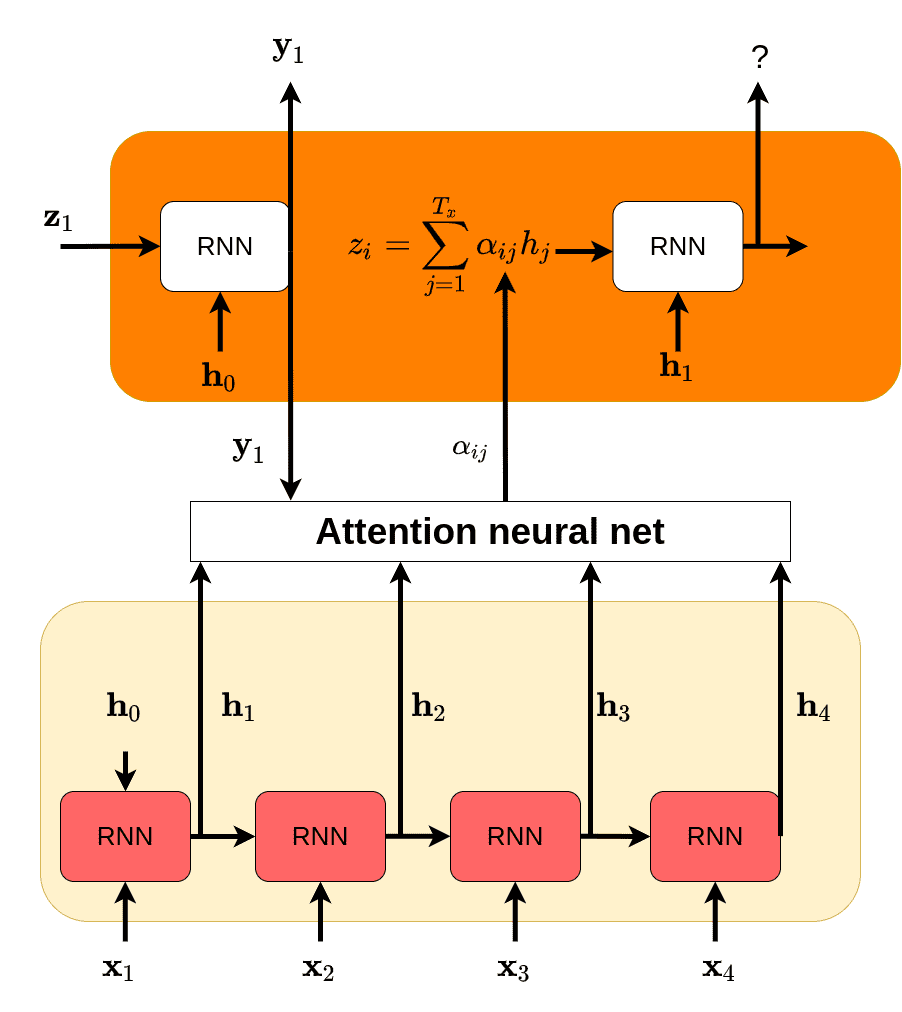
In the Attention mechanism, the attention scoring step determines how much importance each hidden state of the encoder should receive when generating the next word in the target sentence. This step quantifies the alignment or similarity between the current state of the decoder and each hidden state of the encoder. The scoring process essentially helps the model decide which parts of the source sentence are most relevant for generating the current word in the translation.
The scoring process involves a mathematical operation, often a dot product or another similarity metric, to compare the current hidden state of the decoder
Let's use a simple scoring function for attention scoring.
Score(
Assuming:
Score
1 2 3 4=0.08+0.05+0.06 =0.19
This score indicates the degree of alignment or similarity between the current state of the decoder and the hidden state of the encoder. Higher scores suggest stronger alignment and relevance, while lower scores suggest less relevance.
In more complex scenarios, different scoring functions can be used to compute these Attention scores, such as Cosine similarity or learned functions. The idea is to capture the semantic connection between the encoder's hidden states and the decoder's current state, helping the model to focus on the most important parts of the source sentence for generating accurate translations.
These attention scores will then be used to calculate attention weights that determine how much emphasis each hidden state of the encoder should receive when computing the context vector.
Step 5: Attention Weights:
In the Attention mechanism, the attention weights determine how much focus or importance should be given to each hidden state of the encoder when generating the current word in the target sentence. These weights quantify the alignment or relevance between the decoder's current state and each hidden state of the encoder. The attention weights essentially indicate how much attention the decoder should pay to each part of the source sentence.
The attention weights are calculated using a Softmax function applied to the Attention scores calculated in the previous step
Assuming there's only one time step, the attention weight is:
The attention weights are crucial because they determine how much each hidden state of the encoder contributes to generating the current word in the target sentence. By applying the Softmax function, we ensure that the model assigns the appropriate importance to each part of the source sentence based on its relevance to the current translation step. This mechanism allows the model to focus on the most relevant parts of the source sentence, leading to more accurate and contextually meaningful translations.
Step 6: Context Vector:
The Context Vector represents a summarized representation of the relevant parts of the source sentence, weighted by the attention scores. It captures the information that the model has decided is most important for generating the current word in the target sentence. The context vector is formed by taking a weighted sum of the encoder's hidden states using the attention weights.
Context Vector=
1 2=1.0 × [0.2,0.5,−0.3] =[0.2,0.5,−0.3]
The context vector captures the entire information of the hidden state
Please note that this is a simplified example for illustrative purposes. In a real-world scenario, you would have multiple time steps in the encoder, attention scores would be calculated for each time step, and the context vector would be combined with the decoder state over multiple iterations to generate the entire target sentence.
Sample Code Snippet
1 2 3 4 5 6 7 8 9 10 11 12 13 14# Encoder hidden state encoder_hidden_state = np.array([0.2, 0.5, -0.3]) # Decoder state decoder_state = np.array([0.4, 0.1, -0.2]) # Calculate attention score attention_score = np.dot(encoder_hidden_state, decoder_state) # Apply softmax to calculate attention weights attention_weights = np.exp(attention_score) / np.exp(attention_score) # Calculate context vector context_vector = attention_weights * encoder_hidden_state
Reference:
Must Watch:
- Statquest video on Attention: Attention for Neural Networks, Clearly Explained!