Learning Objectives
- Classification and Sigmoid function
- Activation Functions
- Methods of building Deep Learning models
- Error Functions and Optimizers
In the previous unit, you learned about the working of a Neural Network on a conceptual level.
In this module, you'll understand how all of those concepts are brought into practice by understanding some crucial components of a Neural Network.
Finally, you'll build a model to detect whether a person has heart disease or not.
Classification, Importance of Sigmoid Function, and Recap of Logistic Regression
What is Classification?
Let's learn with some examples:
- In classification, we classify the outcome into two classes (Eg: yes or no)
- Examples:
- Predict whether a transaction is fraudulent or not
- Predict whether to give a loan or not
- Predict whether to give college admission or not
- Note: There can be classification problems with more than two classes, and it is called multi-classification
What is Multi-Classification?
It is as simple as dividing waste into four categories - plastic, glass, metal, and paper (we will discuss multi-classification in later units).

Logistic Regression
- Logistic Regression is one of the basic and popular algorithms for solving binary classification problems
- For each input, logistic regression outputs a probability that this input belongs to the two classes
- Set a probability threshold boundary that determines which class the input belongs to
- Binary classification problems (2 classes):
- Emails (Spam / Not Spam)
- Credit Card Transactions (Fraudulent / Not Fraudulent)
- Loan Default (Yes / No)
Now, you may ask, why don't we use Linear Regression? Why do we need a new algorithm?
Well, you will find all the answers in the video in the next slides.
The video below is a must-watch as the instructor has brilliantly explained logistic regression!
Linear vs. Logistic Regression
- Linear regression is used to solve regression problems with continuous values
- Logistic regression is used to solve classification problems with discrete categories
- Binary classification (Classes 0 and 1)
- Examples:
- Emails (Spam / Not Spam)
- Credit Card Transactions (Fraudulent / Not Fraudulent)
- Loan Default (Yes / No)
- Let's say a data scientist named John wants to predict whether a customer will buy insurance or not
- Remember that linear regression is used to predict a continuous
value where the output (y) may vary between
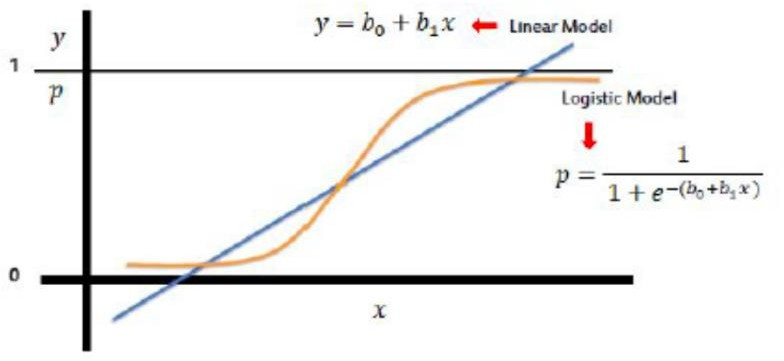
(positive infinity) to (negative infinity), whereas in this case, the target variable (y) takes only two discrete values, 0 (No insurance) and 1 (Yes, got the insurance). - John decides to extend the concepts of linear regression to fulfill his requirement. One approach is to take the output of linear regression and map it between 0 and 1; if the resultant output is below a certain threshold (say 0.5), classify it as No (didn't buy the insurance), whereas if the resulting output is above a certain threshold, classify it as buying the insurance (yes)
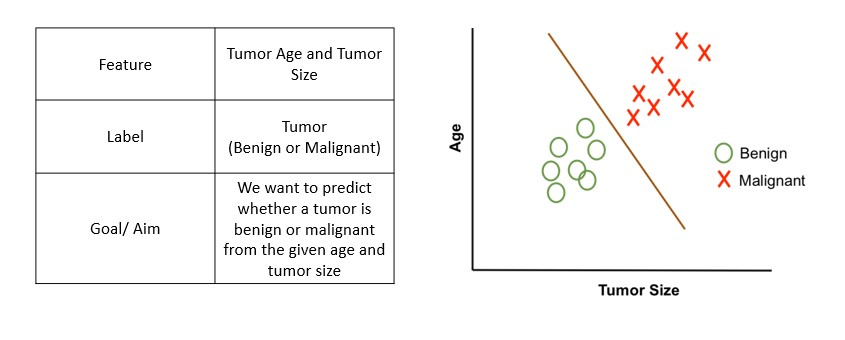
- We then plot a simple linear regression line and set the threshold as 0.5
- Negative class (Insurance = No) – Age on the left side
- Positive class (Insurance = Yes) – Age on the right side
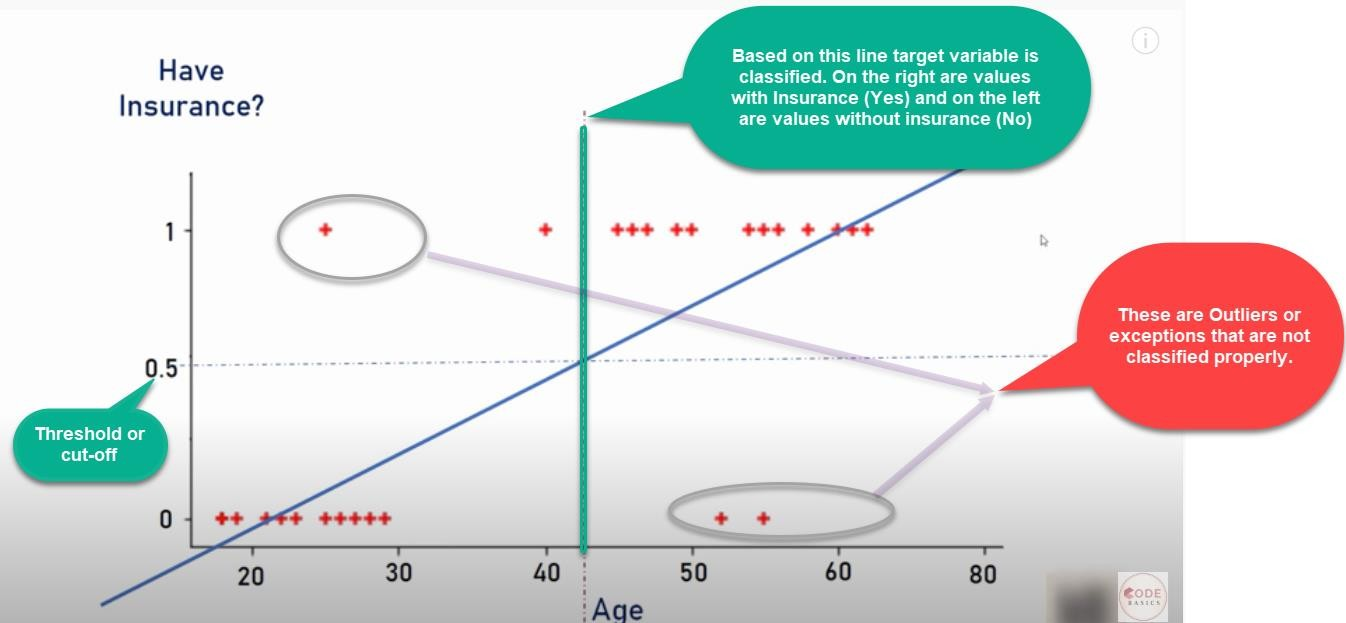
Now, imagine there is an outlier to towards right:
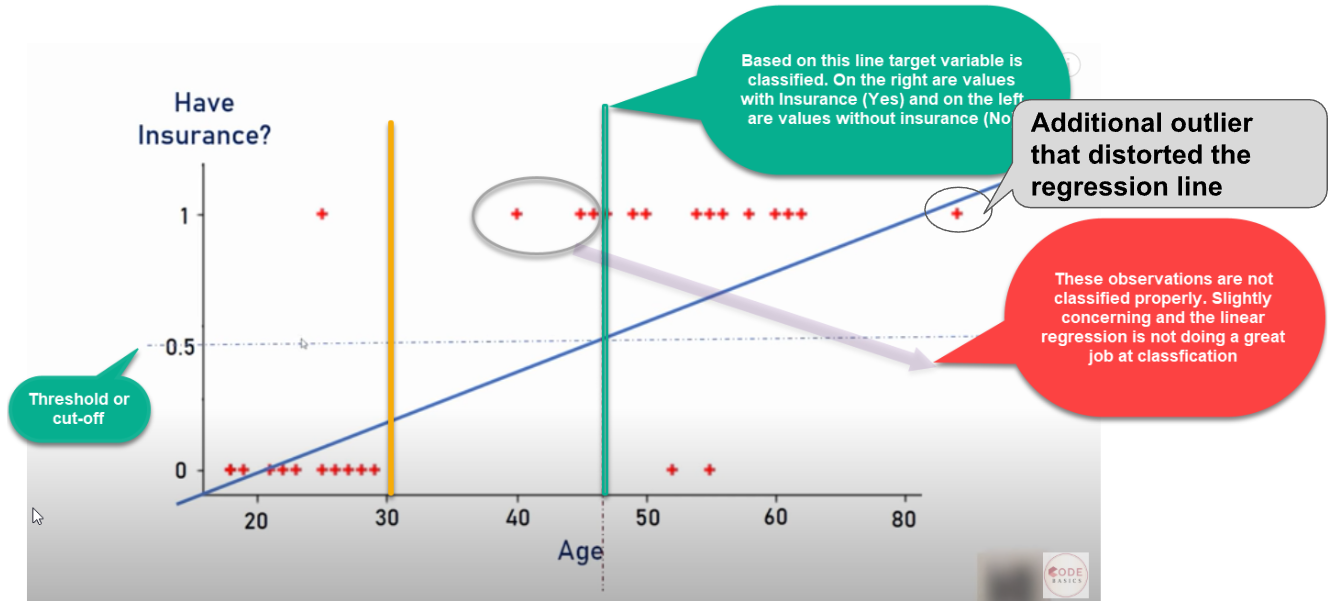
- As we can see, an outlier in the data will distort the whole linear regression line.
- Clearly, the line is unable to differentiate the classes with the linear line fit
- The line should have been at the vertical yellow line, which can divide the positive and negative classes, i.e., yes or no for insurance
Happy John! (Data Scientist)
- Well, life would be much simpler if we had an algorithm that would fit the points like below, right? It is a much better fit compared to the regression line!
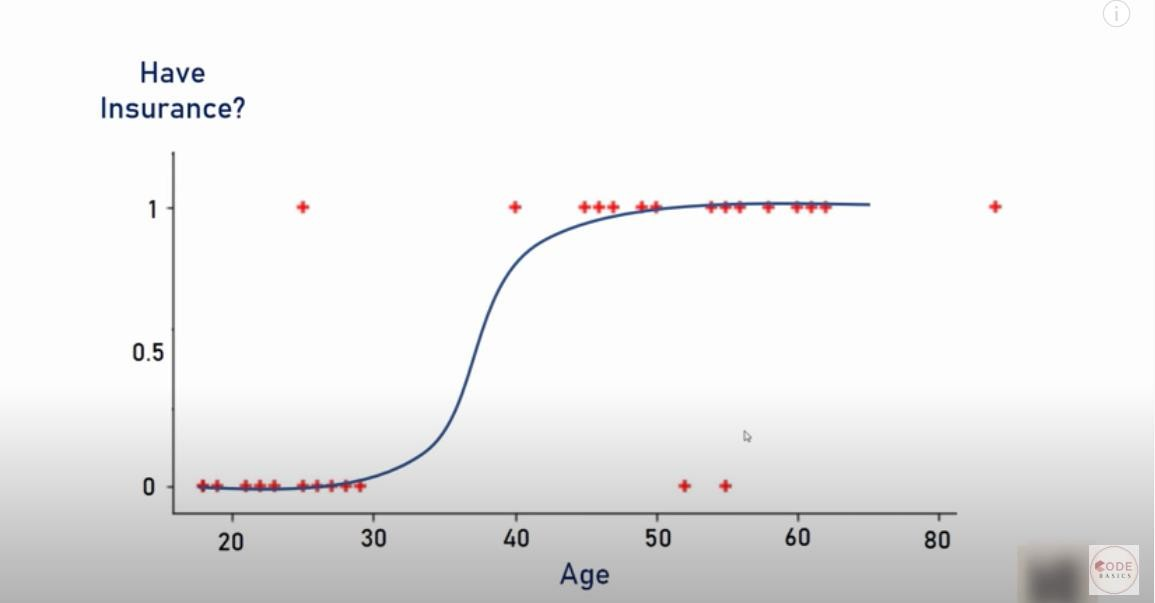
Solution
- Solution – Transform linear regression to a logistic regression curve
- Logistic regression is a Sigmoid function
- Now, what does this sigmoid function do?
- The sigmoid function takes in any real value and gives an output probability between 0 and 1
What are we doing in Logistic Regression?
We will use the real-valued output from a linear regression model between 0 and 1 and classify a new example based on a threshold value. The function used to perform this mapping is the sigmoid function.
The Sigmoid Function is represented by the formula:
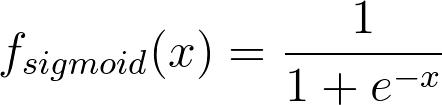
There's no need to go into the depth of how we obtained this formula right now.
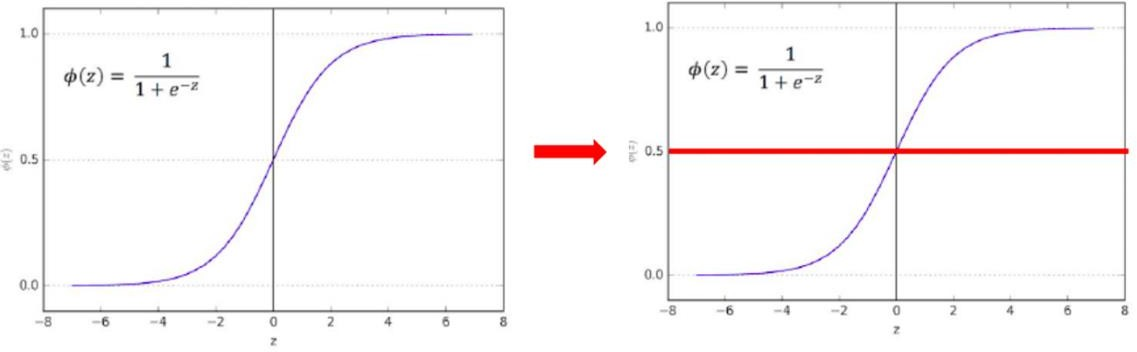
Sigmoid Function (Logistic Function/ Logit)
- Take the linear regression function and put it into the Sigmoid function
- Sigmoid function outputs probability between 0 and 1
- Sigmoid function outputs probability between 0 and 1 (y-axis)
- Default probability threshold is set at 0.5 typically
- Class 0 – Below 0.5
- Class 1 – Above 0.5
Activation Functions
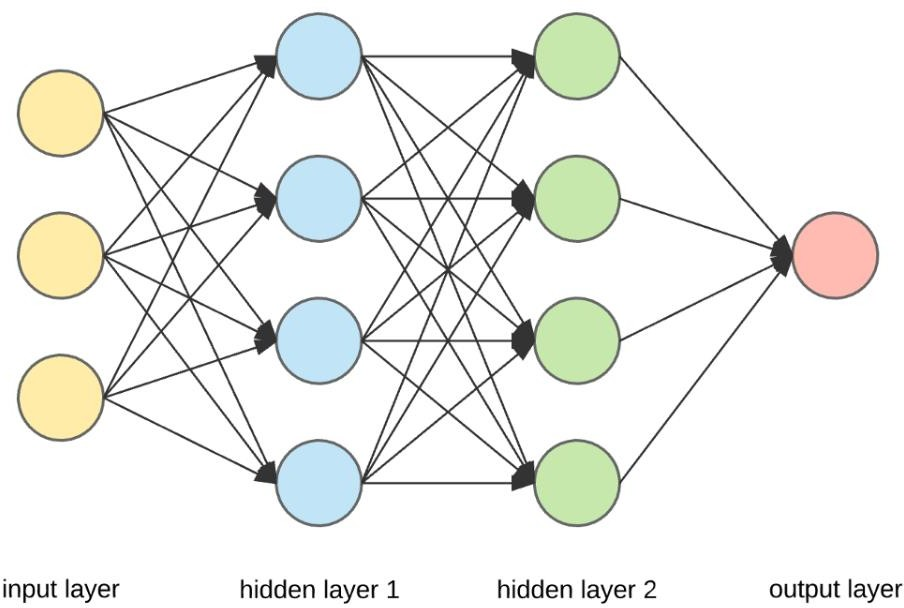
Here's what a Neural Network looks like. Let's dive a bit into what exactly happens inside each neuron.
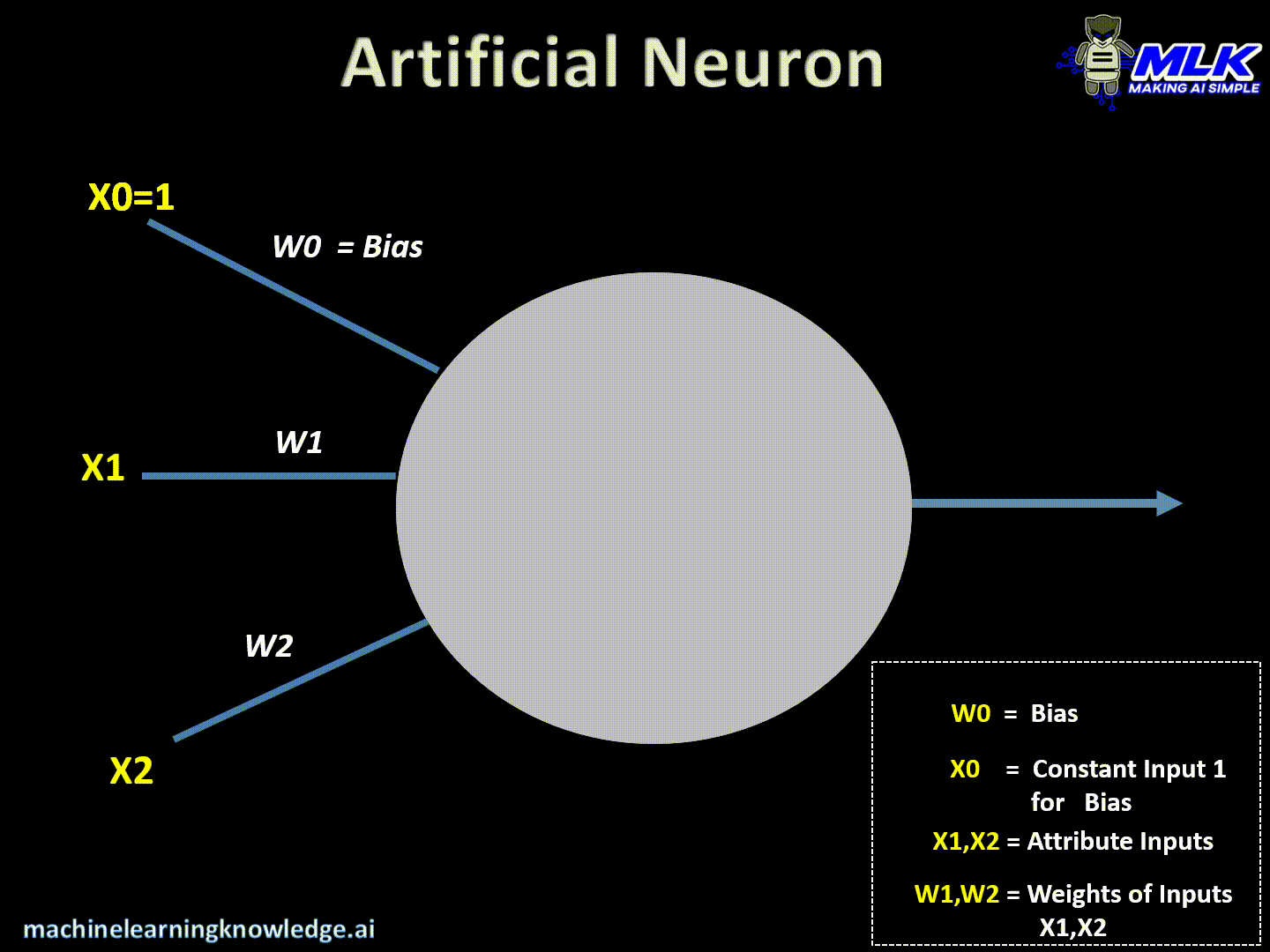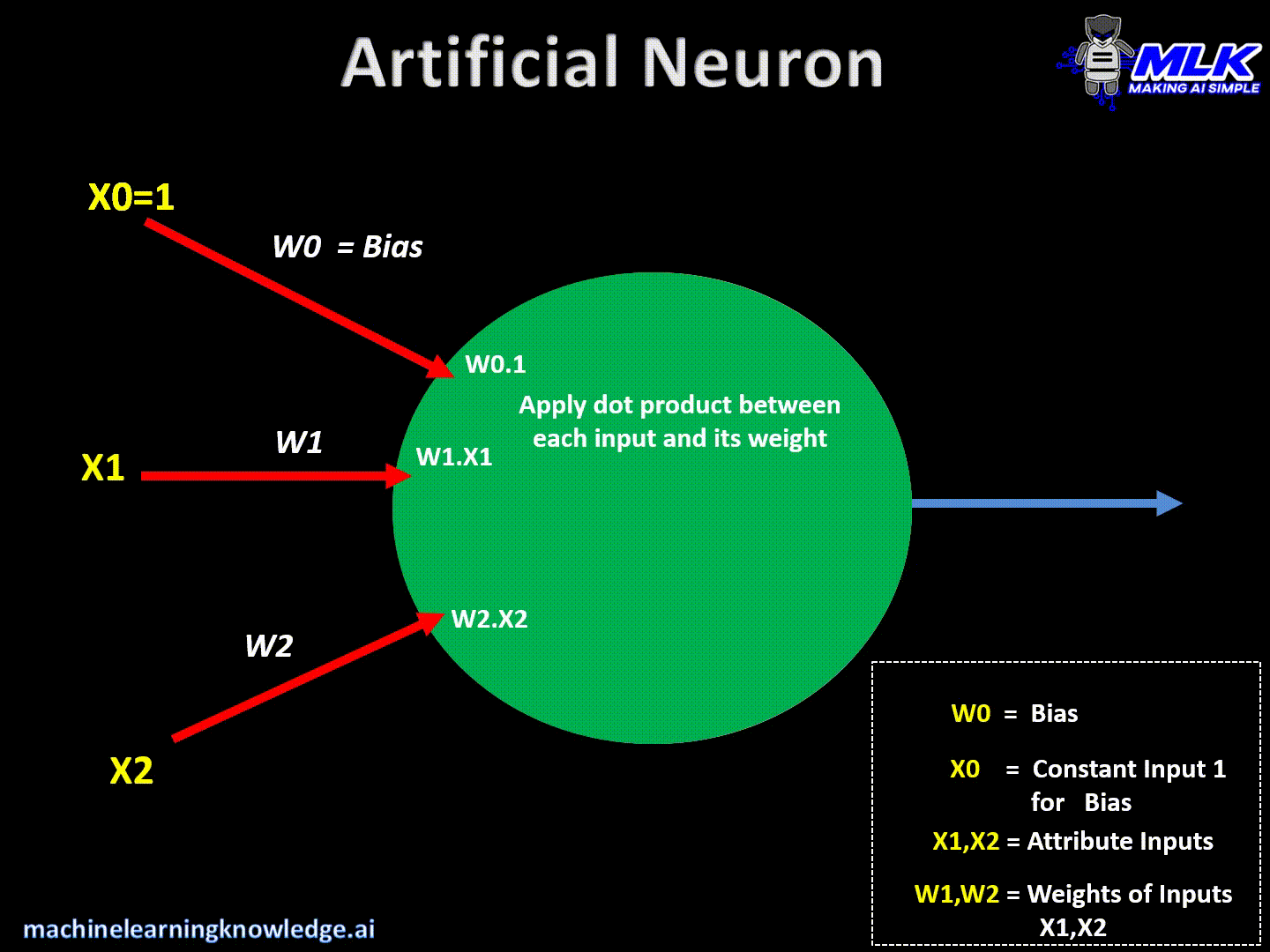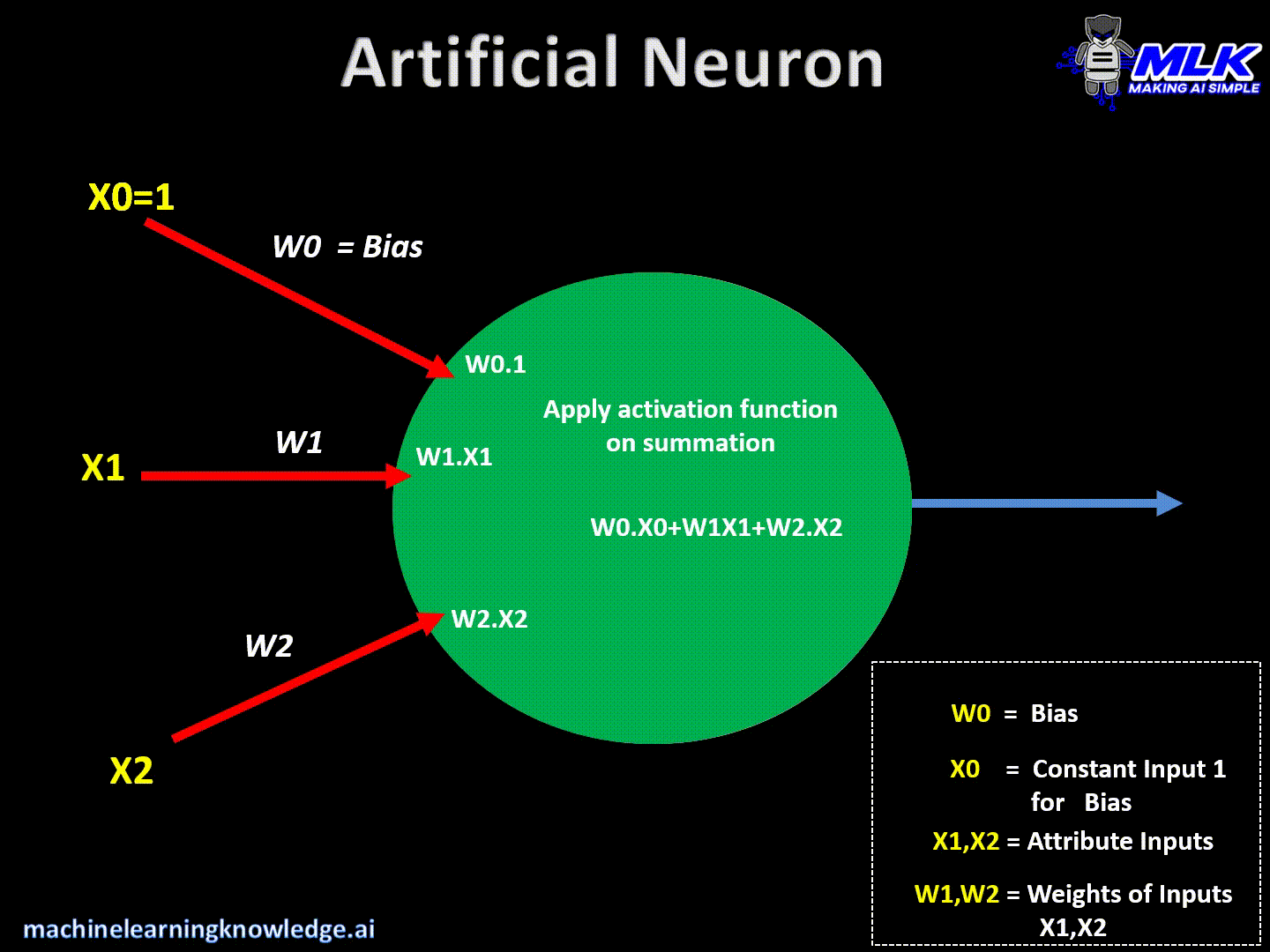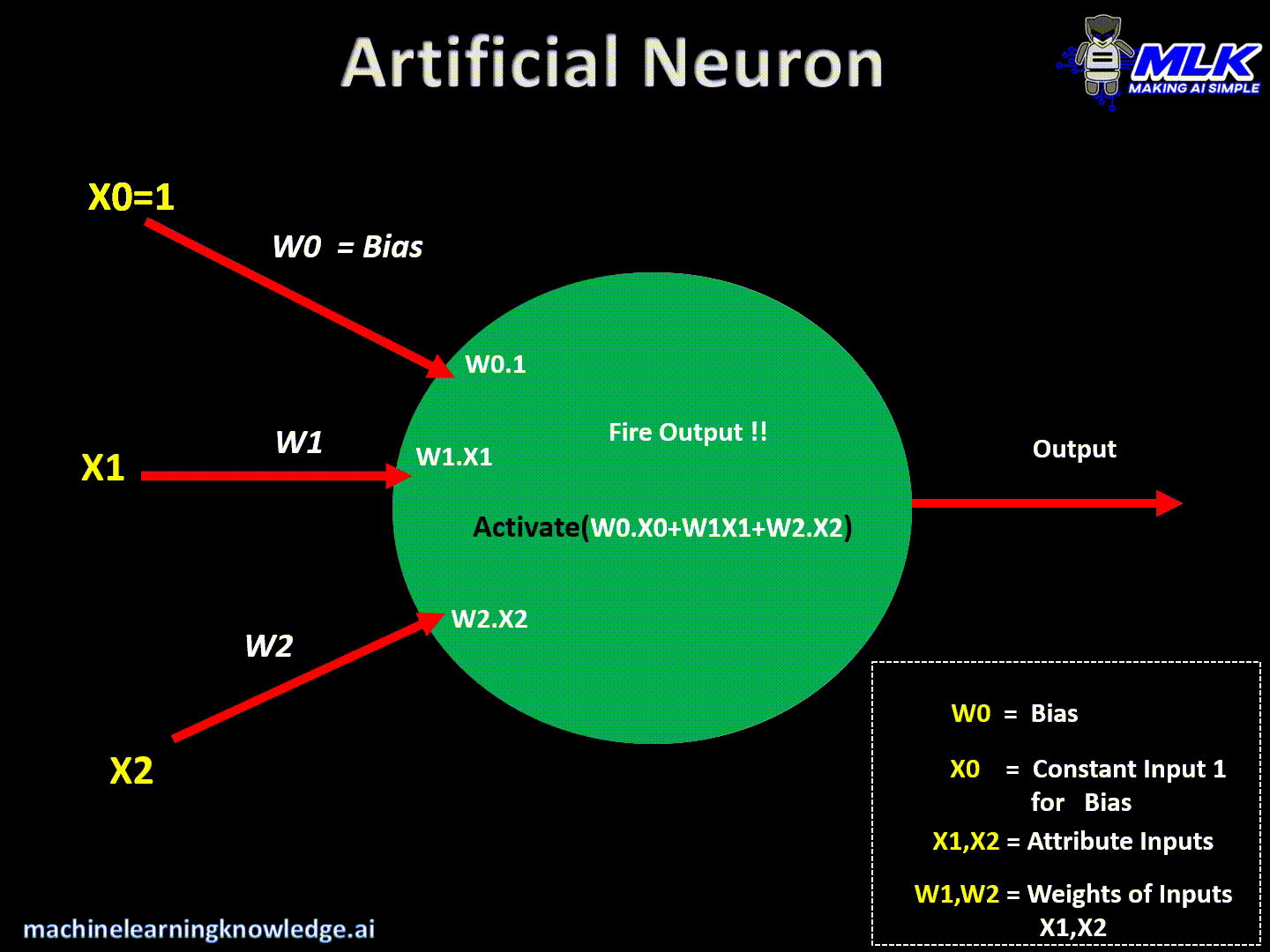
Artificial Neuron – A Quick Recap
Artificial neurons are the basic building blocks of a neural network. It can be considered a computational unit that takes some inputs, applies some transformation to the input, and fires the output. Below are typical steps for computation inside the neuron.
- An artificial neuron takes the inputs and their respective weights.
- It then applies dot products between input values & their weights and sums them up.
- Finally, it applies the activation function on the above summation and fires the output
This can be written in a crude way as below:
Output = Activation(Summation(Inputs*Weights + Bias))
Reference: machinelearningknowledge.ai
Inside a Neuron
- A neuron takes input from the previous layer's neurons (X0,X1,X2)
- It then multiplies each input with some weight (W0, W1, W2) and sums them
- Finally, it applies some activation function and sends/ fires an output.
Activation Functions
Activations functions are an essential part of an artificial neural network.
They decide whether a neuron should be activated(fired) or not based on whether each neuron's input is relevant to the model's prediction.
The purpose of the activation function is to introduce non-linearity into the output of a neuron.
Basically, it helps in creating a boundary like this:
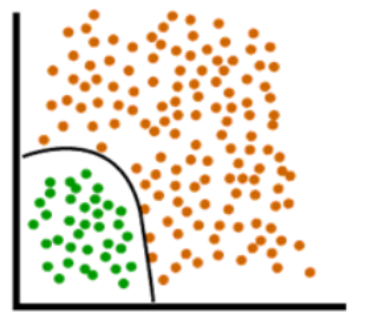
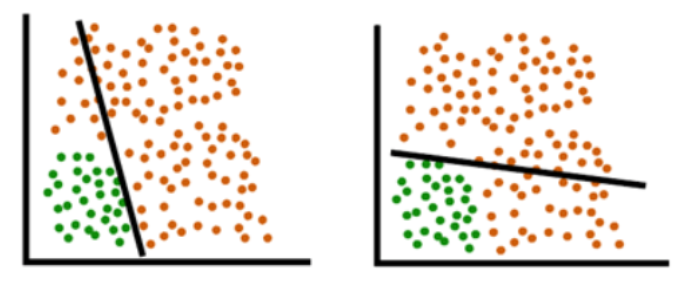
Rather than the linear boundaries(straight lines) that are unable to divide data into two classes:
Types of Activation Functions
- Sigmoid Function
- ReLu
- tanh
- Leaky ReLU
- Softmax Function and more...
Activation Functions - ReLU
Similar to Sigmoid, we have a lot of other activation functions.
Let's have a look at ReLU(Rectified Linear Unit), for example:
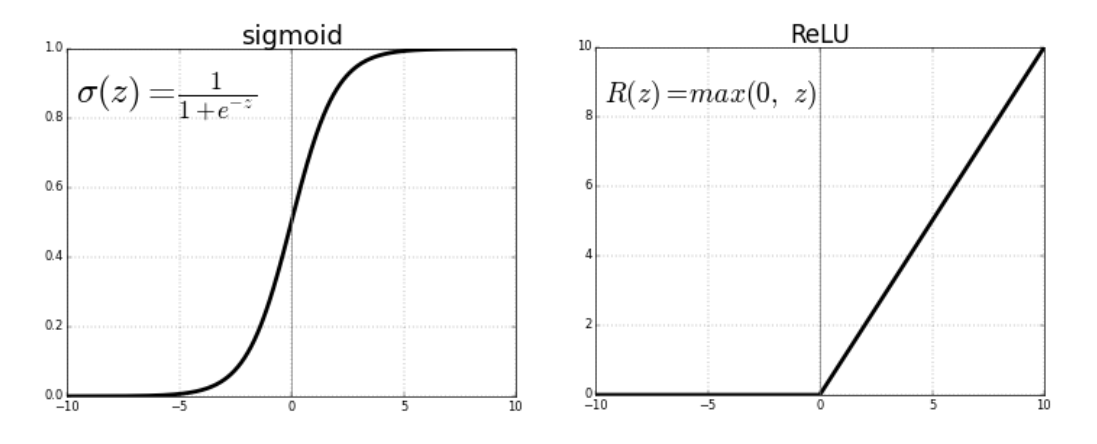
Look at the y-axis of both graphs. Just how Sigmoid had a range of 0 to 1, ReLU has a range of 0 to infinity.
Activation Functions - tanh
Tanh / Hyperbolic Tangent is another popular Activation Function.
It shares a few things in common with the sigmoid activation function. They both look very similar. But while a sigmoid function has a range of 0 and 1, Tanh has a range of -1 and 1.
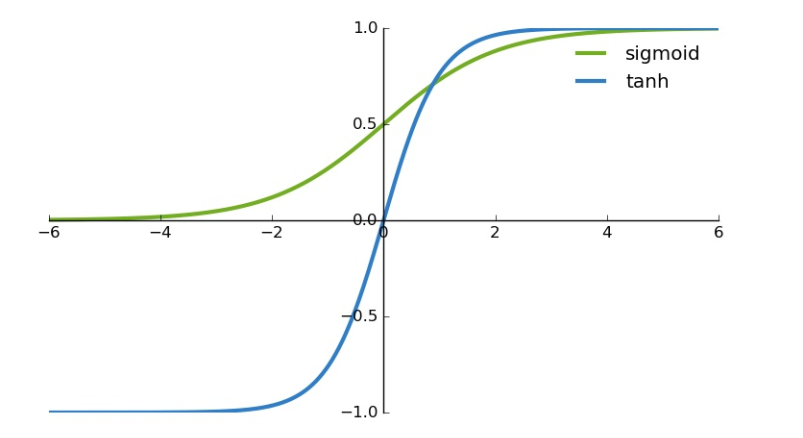
There are a few more activation functions that we'll read about later.
General Guidelines
While choosing an activation function, you can keep the following guidelines in mind:
- Sigmoid is commonly used in the output layer. This is because it helps in giving a probability(value between 0 and 1) which is useful in Binary Classification.
- At places other than the output layer, tanH usually performs better than Sigmoid.
- For Hidden layers, if you are unsure which activation function to use, use ReLU as your default choice.
Note: While these guidelines are helpful, choosing an activation function also depends on trial and error. You should try out a few activation functions and see which works best.
Learn more about Activation Functions
- Animated guide to Activation Functions in Neural Network
- The above article explains the need for activation functions, the different types of activations, as well as the advantages and disadvantages of each.
- We would recommend glancing over it to get an idea through the various gifs present.
- There is no need to dive into the mathematics or worry about the technical terms used there; we'll get to it in some days. The process of learning is slow but surely steady :)
Layers
The neurons in a neural network are divided into layers.

While we know them by the names Input, Hidden and Output till now, Tensorflow doesn't go by those names. It wants the user to specify the type of that particular layer.
For utilizing the different types of layers we have available, Tensorflow provides a submodule called layers that we can import as follows:
1
from tensorflow.keras import layersDense Layer
- A dense layer is just a regular layer of neurons in a neural network.
- It is the most common and frequently used layer.
- Look at the middle layer in the previous image. Each neuron receives input from all the neurons in the previous layer and is thus called densely connected or dense.
- Each output of a dense layer is computed using every input to the layer.
- Dense is one particular type of layer, but we will see many other types as we continue our deep learning journey.
Creating models with Layers
Sequential Model API
There are two ways to create a model using the Layers API:
- A sequential model
The most common model type is the Sequential model, a linear stack of layers. In short, it allows you to build a model layer by layer. Each layer has weights that correspond to the layer that follows it. - A functional model
Unlike the stack of layers in Sequential API, the functional API is a way to build graphs of layers.
As a beginner, the sequential model is the recommended way to get started.
TIP: Learning by Doing
You DON'T need to memorize code given the below notebook. But you must understand what each line of code is doing and should be able to replicate it if required for solving other problems. We have provided explanations as much as possible; if you still don't get certain things, please don't hesitate to ask on the Discord Server!
Let’s practice building Sequential & Functional Models!
- Download
- Extract the zip file
- Open in Jupyter Notebook or Upload on Google Colab
Error functions and Optimizers
Error/Loss Functions
In most learning networks, the error is calculated as the difference between the actual and predicted output.
The function that is used to compute this error is known as the Loss Function.
Different loss functions will give different errors for the same prediction and thus have a considerable effect on the model's performance.
For Binary Classification problems, the loss function usually used is known as Binary Cross Entropy Loss. We don't need to go into the depths of this loss right now. This will be covered in later sessions.
Optimization Function
Error is a function of internal parameters of the model, i.e., weights and bias. For example, m and c in a straight line equation.
For accurate predictions, one needs to minimize the calculated error.
In a neural network, this is done using backpropagation. The current error is typically propagated backward to a previous layer, which is used to modify the weights and bias so that the error is minimized.
The weights are modified using a function called Optimization Function. Optimization functions usually calculate the gradient.
There are a number of Optimizers available such as Adam, RMSProp, SGD, etc. We don't need to get into the theory behind these optimizers, as this will also be covered later.
For our problem, we'll be using RMSProp as the optimizer.
Thus, the components of a neural network model, i.e., the activation function, loss function, and optimization algorithm, play a very important role in efficiently and effectively training a Model to produce accurate results.
Different tasks require a different set of such functions to give the most optimum results.