Learning Objectives
- Feature Importance & Selection
- Benefits of Feature Selection
- Feature Selection Techniques
Feature Importance and Feature Selection
Feature Importance refers to techniques that assign a score to input features based on their ability to predict a target variable.
Feature Selection is the process of automatically or manually selecting features that contribute most to your target variable.
In short, Feature Importance Scores are used for performing Feature Selection.
Suppose we're working on the Iris Classification. We'll first create a baseline model using Logistic Regression. Now, we want to try out Feature Selection and improve our model's performance. On plotting feature importance scores, we obtain the below graph:
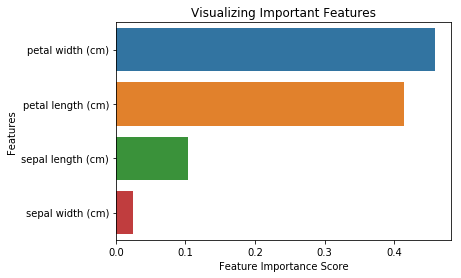
- Feature Importance Scores tell us that Petal width and height are the top 2 features. The rest have a much lower importance score.
- We'll select these two features.
- We'll transform our existing dataset to contain only these two features.
- We'll train our model on this transformed dataset.
- Finally, we'll compare the evaluation metrics of our initial Logistic Regression model with this new model.
Why Feature Selection?
- You already know several optimization methods by now and might think, what's the need to reduce our data by feature selection if we can just optimize?
- There's something known as "The curse of dimensionality". In machine learning,
“dimensionality” = number of features (i.e. input variables) in your dataset. - When the number of features is very large relative to the number of observations(rows) in your dataset, certain algorithms struggle to train effective models. This is called the Curse of Dimensionality.
Curse of dimensionality analogy
- Let's say you have a straight line 100 yards long and dropped a penny somewhere on it. It wouldn't be too hard to find. You walk along the line, and it takes two minutes.
- Now, let's say you have a square 100 yards on each side, and you dropped a penny somewhere on it. It would be pretty hard, like searching across two football fields stuck together. It could take days.
- Now a cube 100 yards across. That's like searching in a 30-story building the size of a football stadium. Ugh.
- The difficulty of searching through the space gets a lot harder as you have more dimensions.
Benefits of performing Feature Selection
You might've understood why feature selection is required by now.
Feature Selection helps us with the following:
- Reduces Overfitting: Less redundant data means less opportunity to make decisions based on noise(irrelevant data).
- Improves Model Performance: Less misleading data means our model's performance improves.
- Reduces Training Time: Less data means that algorithms train faster.
Types of Feature Selection Algorithms
- Filter Methods
- Filter feature selection methods apply a statistical measure to assign a scoring to each feature. E.g., ANOVA, Chi-Square
- Wrapper Methods
- Wrapper methods consider selecting a set of features as a search problem, where different combinations are prepared, evaluated, and compared to other combinations. E.g., Recursive, Boruta
- Embedded/Intrinsic Methods
- Embedded methods learn which features best contribute to the model's accuracy while the model is being created. The most common type of embedded feature selection methods are regularization methods. E.g., Tree-Based Models, Elastic Net Regression
Feature Selection Techniques
- Try and Google 'Feature Selection Techniques'. You'll find that each article will discuss a different set of techniques. The number of Feature Selection Techniques is so extensive that it is not possible to demonstrate all the methods on one dataset.
- It is also important to note that not all techniques will improve the model's performance. Sometimes, the main focus is to reduce the dimension even at the cost of some reduction in performance.
- Different techniques work well on different datasets. It is best to start with a simple technique, see if it improves accuracy, and work your way up by trying out more techniques while comparing the improvement in accuracy.
- We'll implement four techniques in the notebook and see how much improvement occurs by comparing each to a baseline model (basic model without any modifications).
- Recursive Feature Elimination (RFE)
- Feature Importance using Random Forest Classifier
- Boruta
- XGBoost (this is a slightly advanced technique)
There are many more techniques, but the above ones are popular and widely used in the industry.
Notebook link:
Slides Download Link
You can download the slides for this topic from here.