Machine Learning Classification Vs. Regression

Data Science Modeling Process
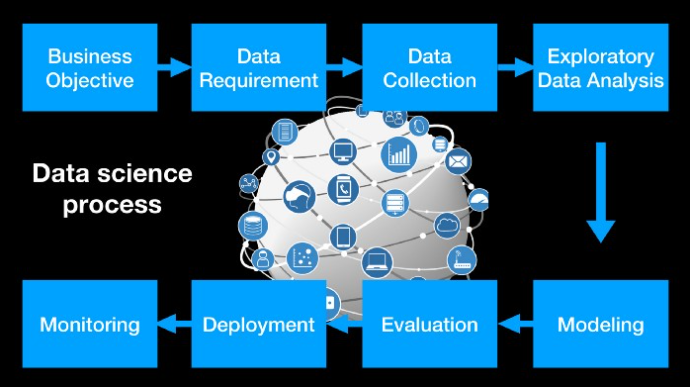
Problem Solving
- Define Objective or understand the problem statement
- Data Requirements
- Data Collection
- Exploratory Data Analysis
- Data Pre-processing
- Build a model
- Understand whether it is a regression or classification problem
- Evaluate
- Optimise
- Production
- Monitor
- You keep Optimising it every now and then
Objective/Problem Statement
- The goal of the model is to predict whether a passenger survived or not in the Titanic disaster, given their age, class, and a few other features.

Data
- We have the data!
Understanding the Data
- PassengerId - this is just a generated Id
- Pclass - which class did the passenger ride - first, second, or third
- Name - self-explanatory
- Sex - male or female
- Age
- SibSp - were the passenger's spouse or siblings with them on the ship
- Parch - were the passenger's parents or children with them on the ship
- Ticket - ticket number
- Fare - ticket price
- Cabin
- Embarked - port of embarkation
- Survived - did the passenger survive the sinking of the Titanic?
Explore the data
- Let's get to the notebook:
https://github.com/dphi-official/Data_Science_Bootcamp/tree/master/Week3
Omitting Irrelevant Variables/Columns
- You shouldn't drop columns or variables just like that! Unless there is a strong premise.
- Id, port, cabin, and name
Split the data into train and test

Model Building - Decision Tree
- Now, what is this decision tree?
- Well, we all might have seen it by now!
- Decision Tree Examples
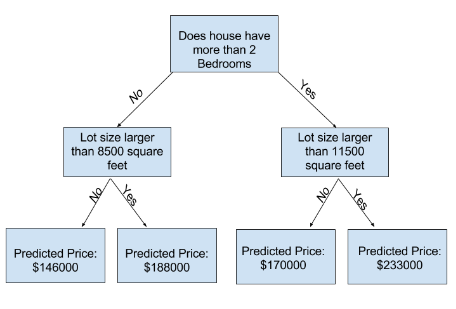
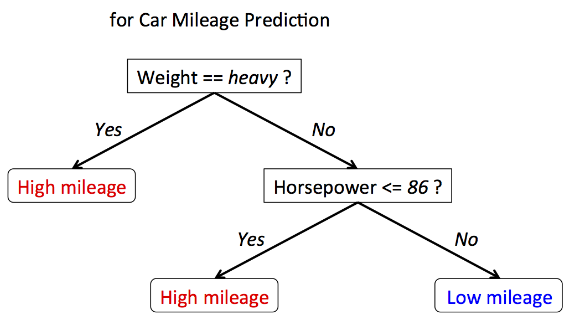
Now, what next?

Let's do it!
Model Evaluation
- Evaluate on test dataset to check the performance!
- Well, we build a model on historical data and expose them to new data that we would see in the future. Technically they will be exposed to unseen data
Overfitting - Underfitting

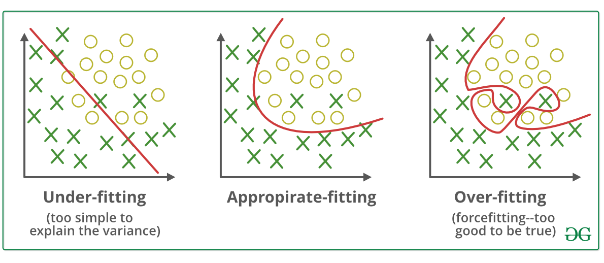
Model Evaluation
We are not done yet. We can improve it significantly.
How? It will follow in due course!
What else can be done in general?
- Feature Selection
- Cross-validation
- Applying different ML Models
- Hyperparameter tuning, etc.
And as data scientists, we must keep optimizing and building better models that derive meaningful results.