Learning Objectives
-
Measures of Dispersion
-
Transformations
-
EDA with Seaborn
-
Additional Python Topics
Measures of Dispersion
-
Range: The difference between the highest and lowest values in the data set.
For a given list of numbers: 10, 20, 40, 10, 70 the range is 70 - 10 = 60. -
Variance: The average of the squared differences from the mean. Steps to calculate variance:
- Calculate mean (mean is nothing but average)
- Find the difference of each data from mean
- Square all the differences
- Take the average of the squares.
-
Standard Deviation: It shows you how much your data is spread around the mean. Its symbol is ???? (the greek letter sigma). It is the square root of the variance.
Standard Deviation
Calculate Variance
Steps to calculate variance:
- Calculate mean
- Find the difference of each data from mean
- Square all the differences
- Take the average of the squares.
Consider the list of numbers: 10, 20, 40, 10, 70.
- Mean of the number is 30.
- Difference of each data from the mean: -20, -10, 10, -20, 40.
- Square of all the differences: 400, 100, 100, 400, 1600
- Take the average of the squares: (400 + 100 + 100 + 400 + 1600) / 5 = 2600 / 5 = 520
Transformation
Some machine learning algorithms are quite sensitive to the scale of the numeric values provided.
Consequently, rescaling the distribution is necessary for the algorithm to converge faster or to provide a more exact solution. Rescaling mutates the range of the values of the features and can affect variance, too. You can perform features rescaling in two ways:
- Using statistical standardization (z-score normalization):
Standardization typically means rescaling data to have a mean of 0 and a standard deviation of 1 (unit variance). - Using the min-max transformation (or normalization):
Normalization typically means rescaling the values into a range of [0,1].
Standardization / Normalization
-
Often, variables in a real dataset come with a wide range of data values.
-
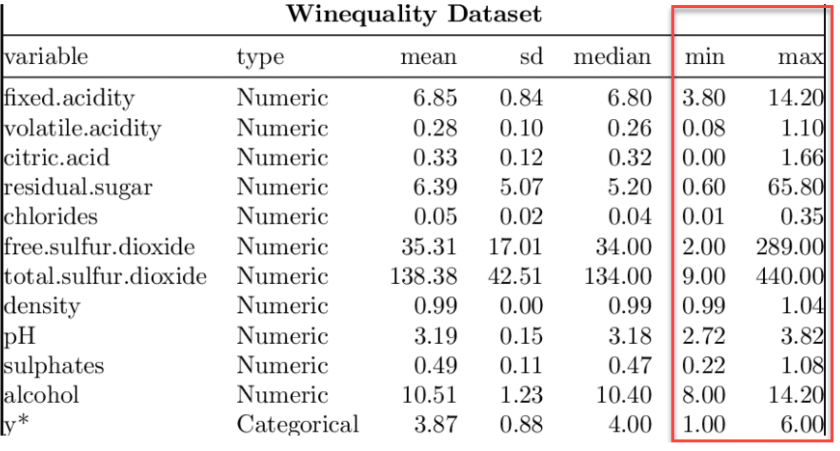
For example let’s look at the wine dataset given below, the fixed.acidity variable has values ranging from 3.8 to 14.2.
-
Similarly, if we look at volatile.acidity, it has values ranging from 0.08 to 1.10. Basically, they are not on a common scale.
Now, how does standardization/normalization help?
- Performing standardization/normalization would bring all the variables in a dataset to a common scale to further help implement various machine learning models (where standardization/normalization is a pre-requisite to applying such models).
- Again, don’t take this for granted; some intelligent algorithms don’t need this, and we will explore them soon!
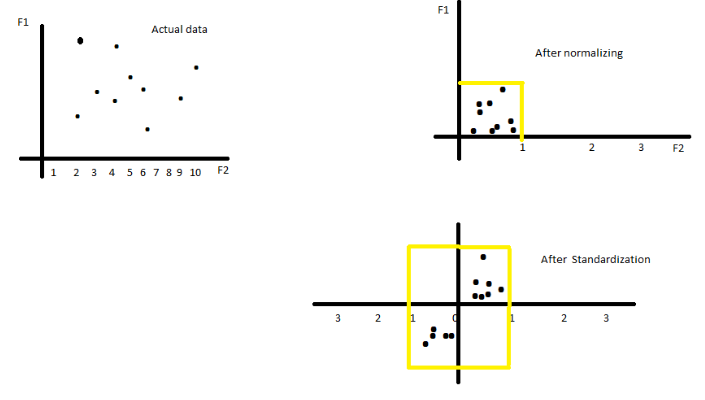
- Look at the above graphs. The actual data is scattered across a wide range.
- Normalisation helps in bringing the whole data within a particular range.
- Standardisation distributes the data such that it now has a mean of 0 and a standard deviation of 1.
EDA with Seaborn
In today’s session, we’ll perform EDA by visualizing data with Seaborn (specifically with scatterplot, countplot, distplot, boxplot, and heatmap).
Please go through the following material to understand these different plots:
https://towardsdatascience.com/how-to-perform-exploratory-data-analysis-with-seaborn-97e3413e841d
Additional Python Topics (Optional)
(This is for self-learning for the session and may not be required in near time - you can consider this as optional)
- A lambda function is a small anonymous function.
- A lambda function can take any number of arguments but only has one expression.
- Syntax:
lambda arguments : expression
- Example:
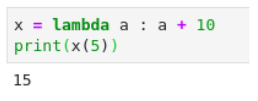
Python Lambda Function
A lambda function that adds 10 to the number passed in as an argument and prints the result:
Here’s a short article about lambda function and its applications: https://www.programiz.com/python-programming/anonymous-function
Python List Comprehension
- One of Python’s most distinctive features is list comprehension, which you can use to create powerful functionality within a single line of code.
- List comprehension is generally more compact and faster than normal functions and loops for creating lists.
- MUST READ: Learn about list comprehension from here: https://www.programiz.com/python-programming/list-comprehension
Python Regular Expression
- A regular expression is a special sequence of characters that helps you match or find other strings or sets of strings, using a specialized syntax held in a pattern.
- Must Read: Go through the following link to get an overview of how regular expressions are used in Python:
https://www.tutorialspoint.com/python/python_reg_expressions.htm - It is usually a confusing topic for most programmers. So don’t worry if you’re not able to understand it fully.
Slide Download Link
You can download the slides for this topic from here.