

In this article, we are going to discover a usecase for GenAI which is speech-to-text conversion using the whisper-1 model from OpenAI. This guide will allow you to ask questions based on the audio file provided as input.
Whisper Model from OpenAI
The Whisper model is an advanced automatic speech recognition (ASR) system developed using a vast and diverse dataset of 680,000 hours of multilingual audio from the web. Designed as an encoder-decoder Transformer, Whisper processes audio in 30-second segments to perform multiple tasks, including speech transcription in various languages and direct translation into English. Its robustness across a wide range of conditions and its superior performance in zero-shot translation tasks make it a valuable tool for practical applications.
GenAI Stack
Here, we will be using AI Planet’s GenAI stack, which is a developer platform simplifying the creation of production-grade Large Language Model (LLM) applications with an intuitive drag-and-drop interface. First of all, we need to go to app.aiplanet.com to log in and create a new stack. Then you need to click on the “New Stack” button.
Building the Stack
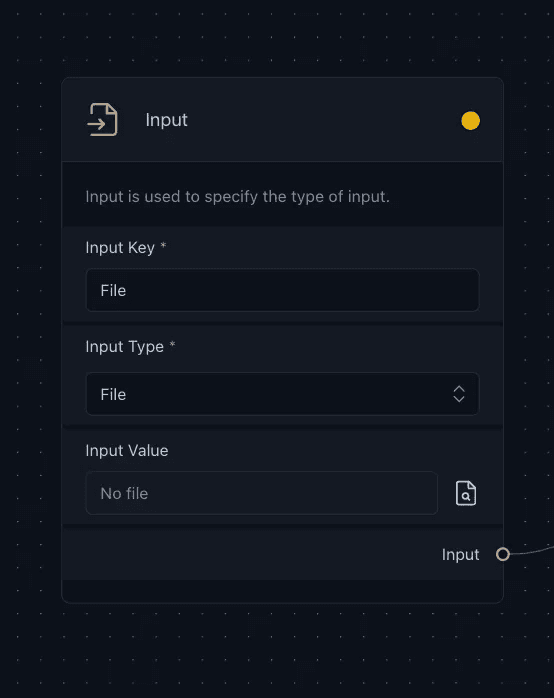
Input Component — Data Loading
We need to specify an input component, which serves as an entry point of the data to the application and it is designed to accept three types of input values: Text, File, and URL. By integrating this component, users can conveniently upload PDFs, enter text, or provide URLs directly through the deployed chat interface’s sidebar.
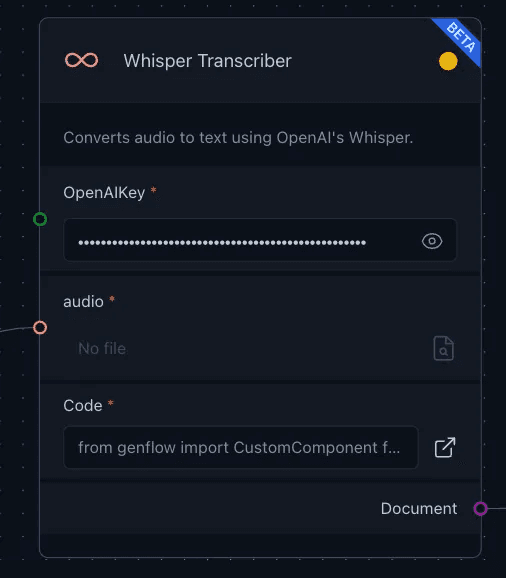
Custom Component — speech-to-text conversion
Then we need to connect the output of the Input component to a custom component, which is designed to integrate specific functionalities tailored to the application’s needs. In this case, the custom component is a Whisper Transcriber Loader that processes audio transcripts with the user-specified model, which is whisper-1 in this case. We can alter the build settings by changing the code in the custom component. This setup allows for dynamic and customizable user interactions within the GenAI Stack environment. Here, this custom component takes on the primary task of converting speech to text.
Code:
Import modules for the required components
Define parameters used for required components
To integrate a speech-to-text converter from LangChain into GenAI Stack, define a class and inherit the custom component. Each component necessitates a display name, description, and a build_config function which specifies the desired parameters that should be appropriately reflected on the user interface (UI).
Initiate the custom component
These parameters will help define and communicate the necessary information for the custom loader within the UI. Once all the essential parameters are defined, utilize the build(**kwargs) method to instantiate the custom component with the specified configurations.
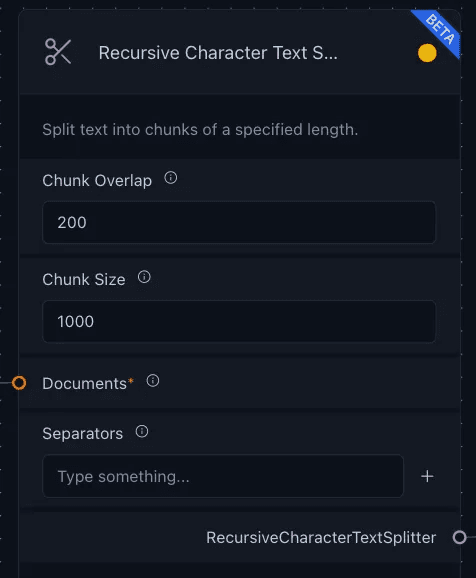
Text Splitter — chunking the text
We also need to connect the output of the custom component to the text-splitter, which tailors the text for optimal context retrieval within the GenAI Stack. The RecursiveCharacterTextSplitter, for instance, breaks down lengthy texts into smaller, context-aligned chunks using parameters like chunk size and overlap, ensuring proximity of related content. This seamless integration streamlines the text manipulation process, enhancing the application efficiency.
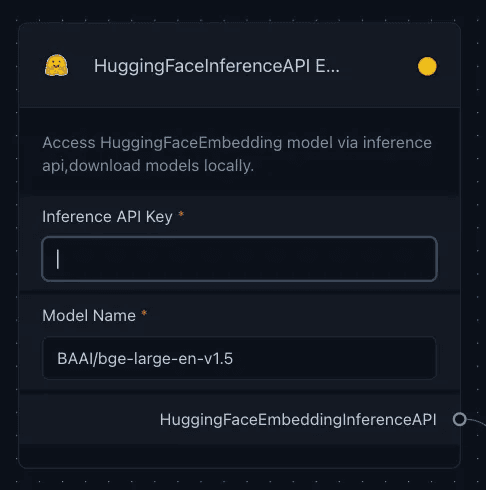
Embedding Model — converting text to numerical form
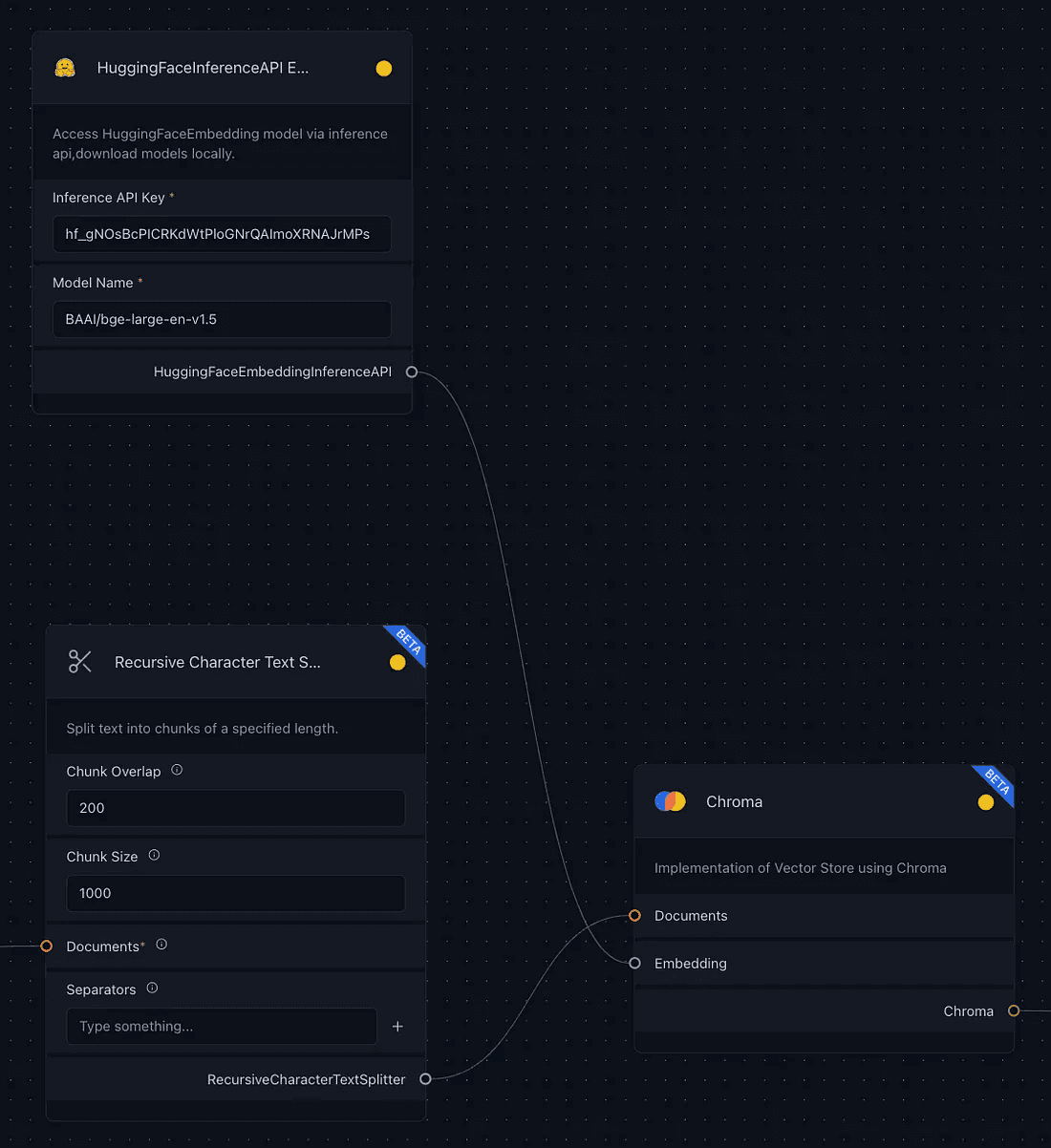
Then we need to create embeddings, which is a process of converting text into numerical vectors to capture semantic relationships in a computer-digestible format. This can be done by using the Hugging Face Inference API from Embeddings, which simplifies embedding generation by eliminating the need for local model downloads. Just provide your Hugging Face Access Token in the API Key field and select a model from the MTEB Leaderboard to seamlessly integrate these embeddings into the Vector Store for further application.
Vector Store — storing the embeddings
After generating the embeddings, we need to connect the embedding component and the text-splitter to a specific vector store, which is ChromaDB in this case. Vector stores are databases designed to manage and retrieve vector embeddings efficiently, facilitating operations like semantic search and relationship identification based on user queries. In this instance, we connect the Huggingface inference API with the “embedding” and the text-splitter output to the “documents” of the ChromaDB component.
Large Language Model (LLM) — text generation
The entire part above is the retriever part, which retrieves data from the audio file and then processes it into a specific format to return documents on a given query.
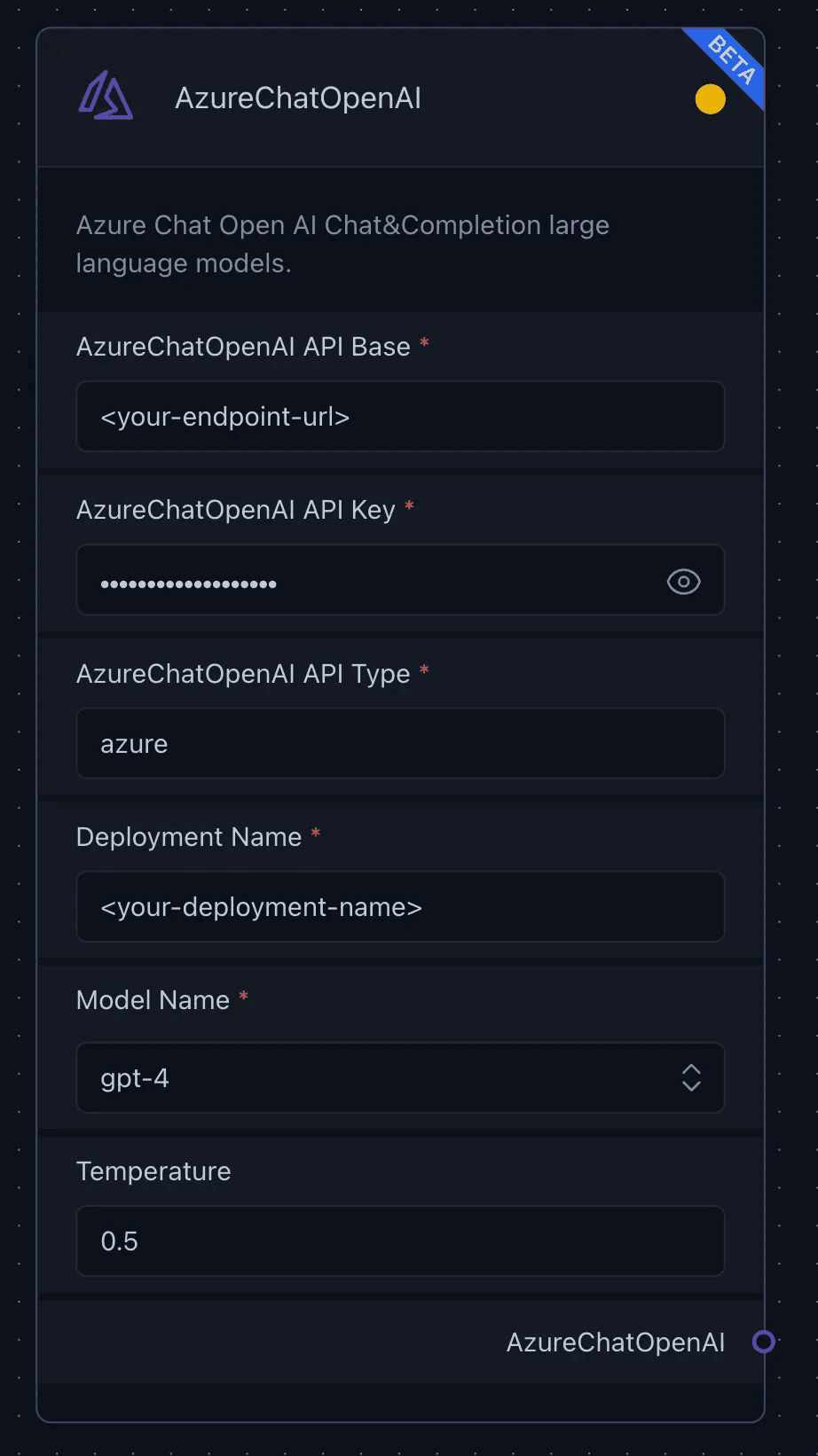
Now, we shift our focus to the Generation section, where we need to define an LLM (Large Language Model) in the first place. In this scenario, we will utilize the AzureChatOpenAI LLM, which provides access to OpenAI’s powerful language models, including the GPT-4 and GPT-3.5-Turbo series. The integration includes some parameters which are:
AzureChatOpenAI API Base, which specifies the Azure Cloud endpoint base URL.
AzureChatOpenAI API Key, which is required to authenticate and access the AzureChatOpenAI service.
AzureChatOpenAI API, which is set by default to ‘Azure’.
Deployment Name, which identifies the deployment name created on Azure’s Model deployments.
Model Name, which specifies access to GPT-4 models under AzureChatOpenAI.
API Version, which indicates the API version, is generally tied to the datetime of the method call.
Max Tokens, which defines the maximum sequence length for the model’s responses.
Temperature, which adjusts the randomness or creativity of the responses.
Chains
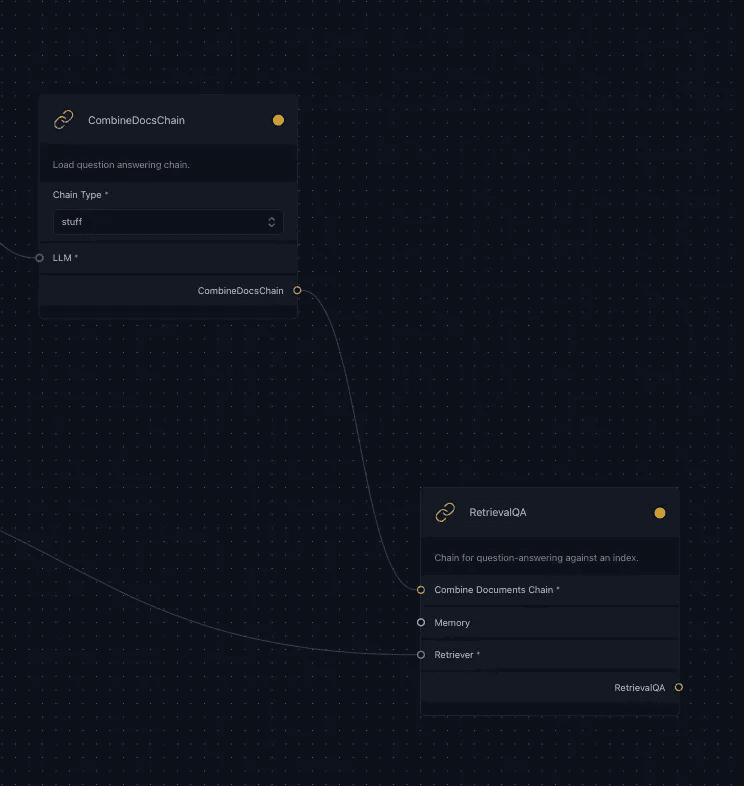
We connect the AzureChatOpenAI LLM component to the CombineDocsChain, which is a sophisticated mechanism within the Stack to streamline the integration and processing of multiple documents. This chain is being used to finally connect the retriever components with the generation components using the RetrievalQA Chain to fetch relevant documents and generate answers for a given question based on the retrieved documents.
Execute your stack
Finally, we build the entire stack using the build button at the bottom right section of our screen. After the build is complete, the Chat Option activates, and you can now chat with your audio. You can also deploy the Stack by clicking on the deploy button in the navigation bar on top.
Chat Interface
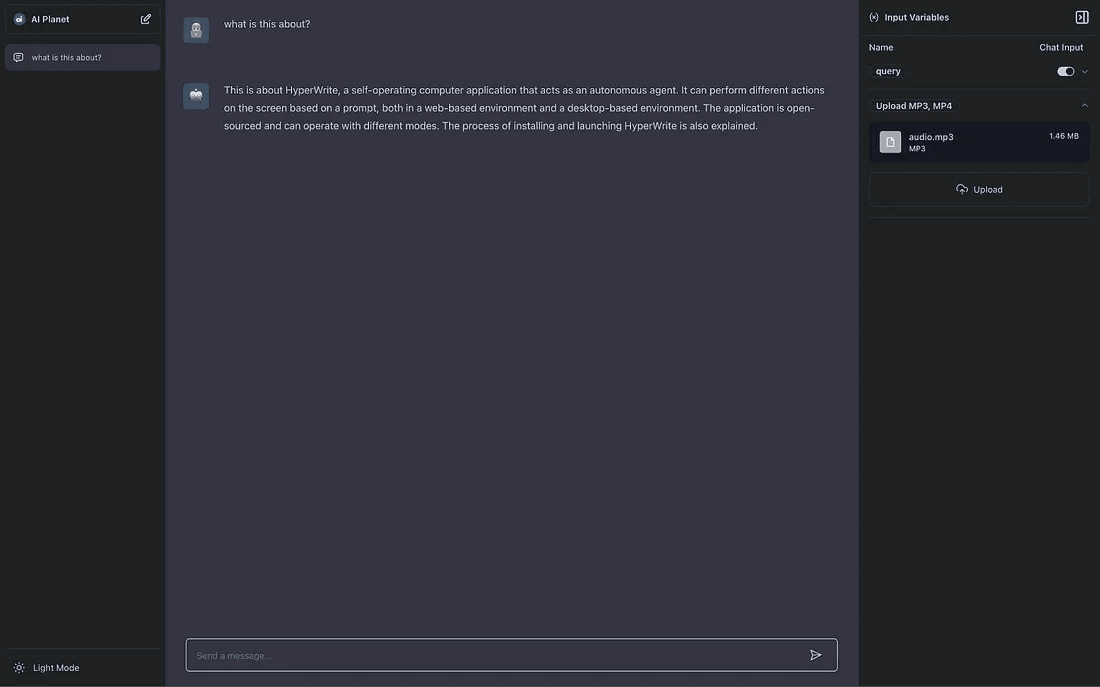
The chat interface of GenAI Stack offers a user-friendly experience and functionality for interacting with the model and customizing the prompt. The sidebar provides options that allow users to view and edit pre-defined prompt variables (queries). This feature allows quick experimentation by enabling the modification of variable values directly within the chat interface.
This tool is completely no-code. Look into some of the usecases and add your Stacks here: github.com/aiplanethub/ai-stacks/