
In today’s AI era, we have seen applications that allow us to chat with data, such as understanding the crux of a large book or report by simply uploading the file and querying it. These applications use Retrieval Augmented Generation (RAG): a method (or pipeline) that leverages the capabilities of LLM to generate content based on prompts and provided data. Unlike traditional methods relying solely on training data, RAG incorporates context into queries which reduces LLM hallucinations by directing the model to consult the source data before responding.
BeyondLLM is an open-source framework that simplifies the development of RAG applications, LLM evaluations, observability, and more in just a few lines of code.
RAG with BeyondLLM
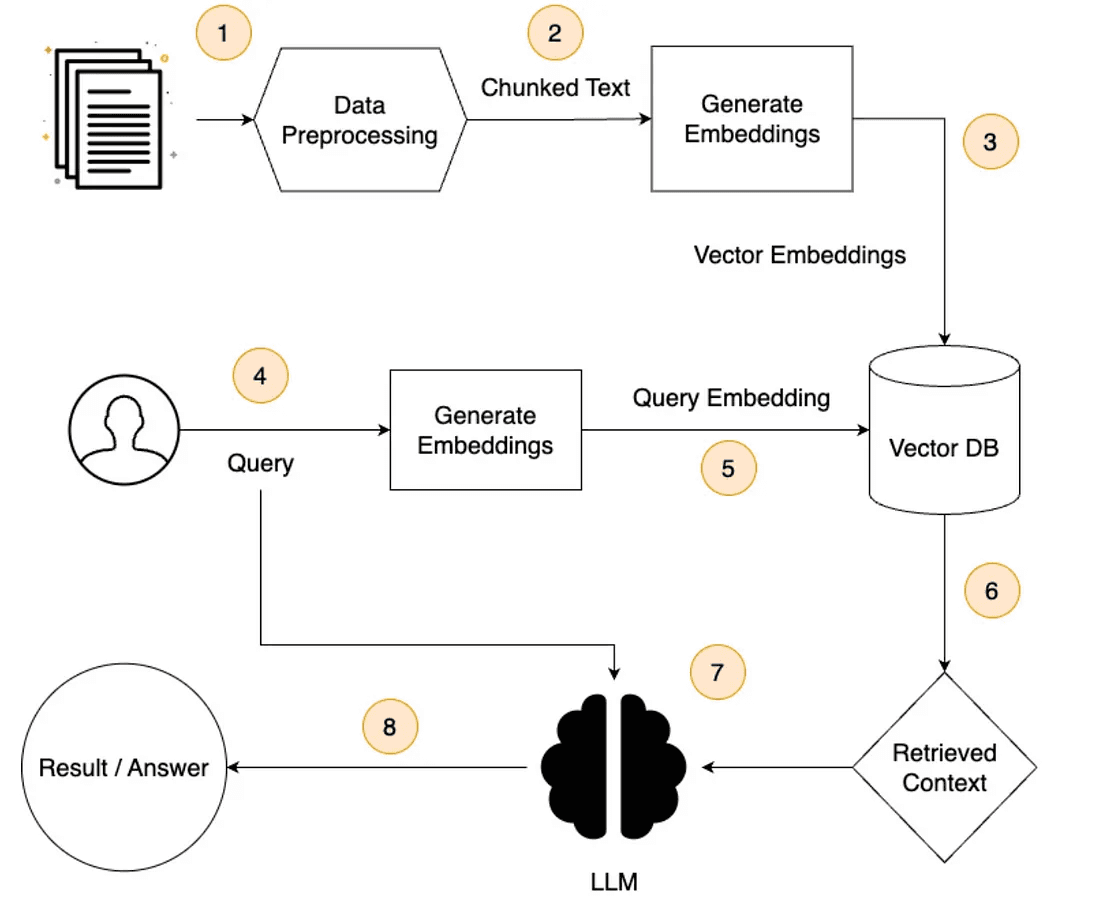
In RAG (Retrieval-Augmented Generation), data is initially loaded in formats (such as PDF and DOCX) and then preprocessed into smaller chunks to fit within the limited context length of the LLM. Next, numerical representations, known as embeddings, are generated using an embedding model. These embeddings enable similarity comparisons during the retrieval of relevant information for a query. The embeddings are stored in a vector database, optimized for efficient storage. When a query is asked, the most similar documents are retrieved by comparing the query vector to all vectors in the database using similarity search techniques. The retrieved documents, along with the query, are then passed to the LLM, which generates the response.
When retrieved documents don’t fully satisfy or answer the query, advanced retrievers can be used. These techniques enhance document retrieval by combining keyword search with similarity search, assessing relevance, and using other sophisticated methods.
Now that we understand what a RAG pipeline is, let’s build one and explore its core concepts.
First, we need a source file for initial ingestion, preprocessing, storage, and retrieval. The `beyondllm.source` module provides various loaders, from PDFs to YouTube videos (using URL). Within the source function, we can specify text-splitting parameters like `chunk_size` and `chunk_overlap`. Preprocessing is necessary because larger chunks are unsuitable for LLMs, which have a limited context length.
Next, we need an embedding model to convert the chunked text documents into numerical embeddings. This process facilitates retrievers in comparing queries with embeddings or vectors rather than plain text. BeyondLLM offers several embedding models with various characteristics and performance levels, with the default being the Gemini Embedding model. For this example, we are using the “BAAI/bge-small-en-v1.5” model from Huggingface Hub.
Note that for accessing the embedding model, we need to define an environment variable named “HF_TOKEN” that has the value of our actual HuggingFace Hub token.
Now, we define the retriever, which uses an advanced cross-rerank technique to retrieve specific chunked text. This method compares the query and document embeddings directly, often resulting in more accurate relevance assessments.
A Large Language Model (LLM) utilizes the retrieved documents and the user’s query to generate a coherent, human-like response. The retrieved documents offer the context of the LLM rather than providing the actual answer. For this purpose, we are using the “mistralai/Mistral-7B-Instruct-v0.2” model from Huggingface Hub.
Next, we integrate all the components using the `generator.Generate` method in the BeyondLLM framework. This approach is similar to using chains to link the retriever and generator components in an RAG pipeline. Additionally, we provide the system prompt to the pipeline.
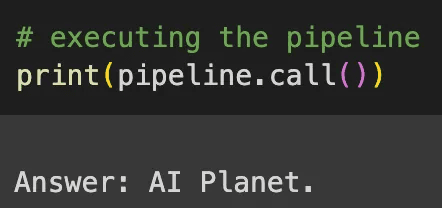
Now, we execute the pipeline after defining and building the entire RAG pipeline.
As a result, we obtain an output that lists the tools used in the video as specified in the query or question. The output should be formatted as follows:
Evaluation Metrics
Thus, we have constructed a complete RAG pipeline that ingests data, creates embeddings, retrieves information, and answers questions with the help of an LLM. But this is not the end. Next, we will evaluate the pipeline’s performance using the evaluation metrics available in the BeyondLLM framework: Context Relevance, Groundedness, Answer Relevance, RAG Triads, and Ground Truth.
Context Relevance — It measures the relevance of the chunks retrieved by the auto_retriever about the user’s query.
Answer Relevance — It assesses the LLM’s ability to generate useful and appropriate answers, reflecting its utility in practical scenarios.
Groundedness — It determines how well the language model’s responses are related to the information retrieved by the auto_retriever, aiming to identify any hallucinated content.
Ground Truth — Measures the alignment between the LLM’s response and a predefined correct answer provided by the user.
RAG Triad — This method directly calculates all three key evaluation metrics, mentioned above.
In this case, we will use the RAG Triad method.
Also, note that each evaluation benchmark uses a scoring range from 0 to 10.
The output should look like this:

Reference
Try out this usecase with the BeyondLLM framework on Colab
Read the BeyondLLM documentation and create new use cases.
While you are here, don’t forget to ⭐️ the repo.